![[Kernel of Linux] 4. Process Management (1)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FMPXIx%2FbtrmbVC1VLF%2FAAAAAAAAAAAAAAAAAAAAAHqKiHGR7mtcfq34ScNaA7FQ10gSLP-wAE0oy-jm3PJ_%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1753973999%26allow_ip%3D%26allow_referer%3D%26signature%3DlDBxG3o5nutPqdKCs4xddesLIvk%253D)
지난 강의 요약 - System Call (2)
system call의 대표적인 함수 몇 가지를 살펴보았고 system call로 인한 context switch 동작까지 이해했다.
1. PCB in Linux

linux에서 프로세스마다 가지고 있는 프로세스 메타데이터가 PCB라는 것은 이제 분명하다. 이제 이 PCB가 linux에서 어떻게 구현되어 있는지 알아보자.
PCB가 저장하고 있는 여러 값들이 있는데 이는 크게 6개의 struct로 나뉘어 있다. task_struct 구조체를 메인으로 해서 files, fs(file system), tty(터미널), mm(main memory), signals 구조체가 담겨 있다.

소스 코드를 살펴보면 task_struct 내부에서 포인터의 형태로 나머지 5개의 struct들을 가리키고 있다.

그렇다면 왜 굳이 6 조각으로 나눠놨을까?
이런 경우를 한번 생각해보자. 만약 child를 만들 때 모든 정보들을 copy 해서 만든다고 하면, parent로부터 read & write 하는 시간이 굉장히 오래 걸릴 것이다. 하지만 보통 parent와 child의 tty(터미널)는 같을 것이다. 그렇기 때문에 굳이 다 복사하지 말고 그런 것들은 pointer를 copy 해주면 struct를 copy 하는 것보다 시간이 적게 걸릴 것이다.
정리하자면 parent가 가지고 있는 struct를 child와 함께 share 하면 process를 만드는데 필요한 오버헤드가 줄어드니 이득이란 것이다. 아직 왜 6 조각으로 나누었는지에 대한 정확한 대답은 하지 못했는데 그건 아래의 2가지 경우를 보면 답변이 될 것이다.

먼저 child를 "Process"로 만드는 방법이다. process로 만든다는 것은 완전히 똑같은 것을 그대로 복사하는 것으로 6개의 모든 struct를 그대로 복사한다.

다음으로는 child를 "Thread"로 만드는 방법이다. process로 만드는 방법에 비해 task_struct만을 복사해 나머지 5개의 struct는 parent와 공유하겠다는 뜻이다.
도식화된 그림으로만 보면 이해하기 힘들지 모르겠는데 좀 더 구체적으로 말하자면 process는 서로 따로 행동한다고 보면 되지만, thread는 스택을 제외한 나머지는 parent와 공유하고 있기 때문에 parent에 의존하고 있다고 봐도 무방하다. 위에서 한 질문에 대한 답변을 정리해서 하자면 linux에서 child를 만드는 방식에 있어 두 가지가 존재하기 때문에 공유해도 되는 자원과 그렇지 않은 자원(task_struct)을 구분해놓기 위해 6개로 나눈 것이다.
2. Linux Thread

linux에서 thread라고 하면 이제 이렇게 말할 수 있다. parent's PCB 중에서 task_struct만을 복사해 만드는 child라고 말이다.
그래서 child를 만들 때 overhead가 적게 들 수 있는 것이고 thread의 다른 말로 LWP(Light-Weight Process)라고 한다. 이런 thread를 만들어 주는 과정은 process를 만들 때 사용하는 fork() 함수와는 다른 함수를 쓴다. 바로 clone() 함수다.
2.1 clone() system call

clone() 함수를 호출할 때는 5개의 bits를 인자로 보낸다. 기본적으로 복사해야 할 task_struct를 제외한 나머지 5개의 struct를 선택하는 것이라고 보면 되는데, 1이면 copy, 0이면 share다. clone(00000)으로 호출한다면 linux에서 사용하는 thread(LWP)를 만든다.

clone() system call의 manual이다.
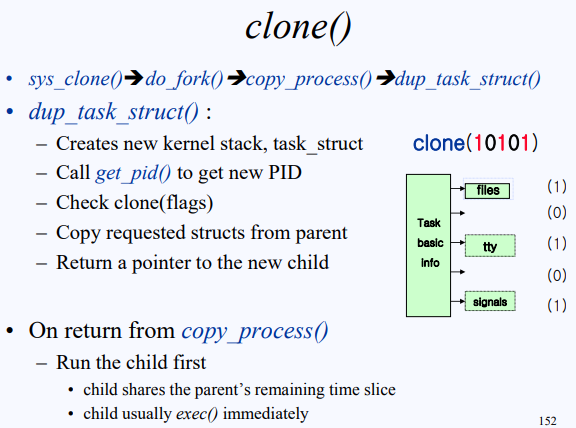
교수님께서는 설명을 넘어가셨지만 이전에 배웠던 커널 지식을 이용해서 간단하게 설명하고 넘어가려 한다.
위에서도 기술했지만 process든 thread든 일단 기본적으로 각자의 task_struct가 필요하다. 그리고 각자의 스택 또한 필요하다. clone() 함수로 넘어오는 인자의 값이 어떻든 말이다. 그래서 기본적으로 task_struct 구조체와 스택은 만든다. 그러고 나서 thread도 하나의 프로세스니 pid 값을 부여해준다. 참고로 get_pid()는 현재 사용하는 가장 마지막 pid에서 +1 한 값을 return 한다. 이후에는 clone(flags)에서 flags를 체크해서 copy 할 건 해주고 공간을 할당하기만 한 child의 task_struct에 parent의 task_struct를 복사해준다.
TMI) task_struct의 위치는 각 프로세스(스레드)의 스택 최상단에 위치한다.
sys_clone() ~ dup_task_struct() 하는 과정 중에서 copy_process() 함수의 return에 의해 child가 먼저 실행되도록 한다. 어떻게 그게 가능한지는 밑의 순서를 보면 알 수 있다.

wake_up_new_task(), set_need_reshed() 함수에 의해서 child process는 parent보다 높은 priority를 갖게 된다. 그렇게 system call이 끝나고 parent's user code로 돌아가기 전에, 커널은 ready list에서 더 높은 priority를 가진 process가 존재하는지 확인한다. 이전에 설정된 값에 의해 커널이 child가 parent보다 먼저 실행되도록 만든다. parent는 강제로 sleep 상태가 된다. 그렇게 child의 소스 코드가 실행된다. 만약 child가 exec() 함수를 호출했다면 image를 덮어 씌우게 되므로 더 이상 parent와 자원을 공유하지 않는다.
3. COW (Copy-on-Write)
여기까지 child를 생성하는 과정과 방법에 대해 알아봤다.
지금까지 배운 내용을 바탕으로 다음과 같은 상황을 떠올려보자. user가 shell에 'ls'라는 명령어를 쳤다. 이때 parent인 shell은 child를 만들어서(fork) 그 위에 ls의 image를 덮어 씌우는(exec) 과정을 진행하게 될 것이다. 이렇게 2개의 과정 중에서 오버헤드가 더 큰 쪽은 exec()이다.
하지만 엔지니어들이 생각하기 시작했다. 위에서 든 ls라는 간단한 명령어를 실행하는데 굳이 수고스럽게 parent의 자원들을 다 copy 하고 어렵게 image를 올릴 필요가 있냐는 것이다. 물론 아닐 수도 있지만 대부분의 상황에서 유용할 것이라는 점은 명확하다. 그렇다면 어떻게 구현할까?

다시 한번 Old UNIX에서 사용하던 방법을 보자. fork()와 exec()을 통해 child를 만든 후 ls image를 오버레이 해준다.

이전과 같은 방식으로는 너무 오래 걸리니 엔지니어들이 생각한 것이 바로 위의 그림이다.
child는 image가 있는 것 같지만 없고 parent와 똑같은 page mapping table만을 가지고 실행된다. 이렇게 되면 instruction이 switching 되는 동안에는 그냥 같이 쓸 수 있다. 문제는 언제 발생하냐면 parent나 child가 write를 시도할 때 발생한다. 이 경우에만 각자 따로 page를 copy 해서 다루게 하면 된다.
정리하자면 평소에는 parent, child가 같은 page table을 사용하고 있다가 둘 중 하나가 modifing을 하려고 할 때만 바뀌는 page를 copy 해서 따로 가지게 하면 될 것이다. 이후 write를 하든지 하면 될 것이다. 이걸 바로 COW(Copy-on-Write)라고 한다. 리소스 공유 문제를 해결하기 위해 등장한 개념이다.

이론 자체는 매우 실용적으로 보이지만 이걸 기존 모델에 copy 하는 부분에 그대로 적용하기에는 무리가 있다. 그 이유는 parent에서 fork()를 한 이후에 wait()가 불릴 때까지 다른 코드를 실행할 수도 있다. 소개한 예제는 간단하기 때문에 바로 wait() 함수를 호출하는 것처럼 보이지만 실제로는 그렇지 않은 경우가 보통일 것이다. 그렇다면 다른 코드를 실행한다는 것은 memory write가 일어날 수 있는 가능성이 있는 것이고 실제로도 얼마 없는 레지스터를 가지고 일을 하려다 보니 컴파일러가 read & write를 자주 한다. (교수님 말씀으로는 1/3 정도 그렇다는데 wait() call만 가지고 그렇게 말씀하시는 건지는 잘 모르겠다.)
그러다 보니 이미 child로 가기도 전에 parent가 COW를 하느라 대부분이 새로 갈아치워 진 page가 된다. child로 넘어가면 이렇게 새로 만든 이론이 아무 쓸모도 없어진다. fork() & exec()으로 child process를 만드는 것과 별반 차이가 없어진다.

linux에서는 이점을 살리기 위해 fork() 함수를 redesign 했다. 원래는 fork()를 호출한 이후에 parent로 바로 돌아갔지만 그렇게 하지 않고 fork()가 child의 priority를 parent의 priority보다 높게 설정해준다.
이렇게 하면 fork()가 끝난 후 커널은 다음으로 실행할 process를 ready list에서 보고 가져온다. 이때 child의 priority가 parent보다 높게 설정되어 있으니까 child가 parent 보다 먼저 exec() 함수를 실행하게 된다. 이렇게 되면 다시 parent로 돌아간다고 하더라도 COW가 발생하는 오버헤드를 없앨 수 있으니 이득이다.
4. Test
강의에서 교수님이 진행하신 실습 내용과 비슷하게 테스트해서 결과를 비교한다. 단 지금 실험 환경은 Linux Kernel v5.14.17 임을 기억해야 한다. 2010년도 강의와는 꽤--나 차이 난다. 그땐 v2.6.23 라고 추정하는데 fork()가 redesign 된 지 얼마 안 된 시점이다. 많은 것이 바뀌었다.
4.1 ONLY fork()
// gcc fork1.c #include <stdio.h> #include <unistd.h> #include <wait.h> int main() { int pid; pid = fork(); if (pid == 0) { printf("Hi, I'm a child.\n"); // execlp("ls", "ls", NULL); } else { printf("Hi, I'm a parent.\n"); // wait(NULL); } }실행 결과:

위에서 배운 대로라면 child가 먼저 출력되고 parent가 나와야 하지만 마치 priority가 같아서 fork로부터 return 한 parent가 먼저 실행된 것처럼 보인다. 아마 exec 계열의 system call이 나오지 않아서 그런 것일까 싶어서 있는 경우도 실험해봤다. 그전에 결과를 확인하면 스크린샷의 마지막 부분에서 parent가 child를 wait() 하지 않고 먼저 종료돼서 child의 출력이 프로그램이 종료된 후 나온 모습도 보인다. 그리고 여기서 궁금해진 점 2가지를 추가로 확인해봤다.
(1) exec()가 없는 소스 코드에서 fork() 함수의 호출은 fork() 후 COW가 얼마나 일어나는지
(2) ftrace 디버깅 툴로 scheduling sequence와 priority 할당 확인
먼저 (1)에 대해 보자.

이미지에서 입력한 명령어인 "cat /proc/[PID]/smaps"를 통해 mapping 된 메모리 정보를 확인할 수 있다. Private_Dirty 부분이 COW를 한 크기를 나타낸다. 보안적 관점에서는 컴파일했을 때 PIE가 적용된 주소를 볼 수 있고, 순서대로 code, data, bss 부분 등에서는 COW를 한 흔적이 보이지 않았다. COW가 일어난 부분은 libc, ld 같은 동적 라이브러리 파일들과 heap, stack에서 4kB 정도로 작게 일어났다.
다음으로 (2)를 보자.
디버깅 때 쓴 스크립트는 이전에 포스팅한 「디버깅을 통해 배우는 리눅스 커널의 구조와 원리」 책 내용 실습 때 사용한 것을 변형해서 사용했다.
#!/bin/bash echo 0 > /sys/kernel/debug/tracing/tracing_on sleep 1 echo "1) tracing off" echo 0 > /sys/kernel/debug/tracing/events/enable sleep 1 echo "2) events disabled" echo mcheck_cpu_init > /sys/kernel/debug/tracing/set_ftrace_filter sleep 1 echo "3) dummy for set_ftrace_filter" echo function > /sys/kernel/debug/tracing/current_tracer sleep 1 echo "4) function tracer enabled" echo 1 > /sys/kernel/debug/tracing/events/sched/sched_switch/enable echo 1 > /sys/kernel/debug/tracing/events/sched/sched_wakeup/enable echo 1 > /sys/kernel/debug/tracing/events/sched/sched_process_exec/enable echo 1 > /sys/kernel/debug/tracing/events/sched/sched_process_exit/enable echo 1 > /sys/kernel/debug/tracing/events/sched/sched_process_fork/enable echo 1 > /sys/kernel/debug/tracing/events/sched/sched_process_wait/enable echo 1 > /sys/kernel/debug/tracing/events/raw_syscalls/enable sleep 1 echo "5) events enabled" echo sched_fork kernel_clone > /sys/kernel/debug/tracing/set_ftrace_filter echo copy_process >> /sys/kernel/debug/tracing/set_ftrace_filter sleep 1 echo "6) set_ftrace_filter enabled" echo 1 > /sys/kernel/debug/tracing/options/func_stack_trace echo 1 > /sys/kernel/debug/tracing/options/sym-offset echo "7) tracer options enabled" echo 1 > /sys/kernel/debug/tracing/tracing_on echo "8) tracing_on"트레이싱 열고 a.out 실행하고 트레이싱 닫은 후 로그 중에서 분석에 필요한 부분을 보자.

지금 보고 있는 부분이 bash shell로부터 fork 된 parent process다. fork() 함수는 deprecated라 자동적으로 sys_clone() 함수를 호출하는 wrapper가 되었다. sys_clone() 함수는 v5.9 까지만 해도 안에서 _do_fork() 함수를 호출했지만 v5.10 부터는 이름이 바뀌어서 kernel_clone()이 되었다. 아무튼 NR 56(56번 syscall)을 통해 bash를 복사해서 PID 2972를 가지는 parent a.out이 생성되었다.
그리고 아래로 좀 더 내려가 보면 child a.out을 생성하는 부분이 보인다.


2972 a.out이 2973 a.out의 child를 생성하는 모습이 보인다(복사한 후에 PID를 +1 해준 걸 확인할 수 있다). 5485번째 줄과 5499번째 줄을 보면 parent가 먼저 exit() 함수로 나가버린 모습을 볼 수 있다. 이건 wait() system call을 parent가 사용하지 않았기 때문에 발생한다고 볼 수 있다. priority 측면에서 살펴보자면 prev_prio, next_prio를 보면 알 수 있다. 바로 눈에 들어오겠지만 parent, child 둘 다 같은 prio(120)을 가지고 있어서 먼저 fork()에서 돌아온 parent가 스케줄링된 것을 확인할 수 있다.
4.2 fork() - exec()
위에서 궁금했던 사항 2개를 그대로 가져와서 이번엔 어떤지 보도록 하자.
(1) exec()가 없는 소스 코드에서 fork() 함수의 호출은 fork() 후 COW가 얼마나 일어나는지
이건 해보기가 좀 어려웠다. 뒤에서 한 번 더 말하겠지만 이 주제 + fork() 함수의 역사에 대해 자세하게 설명한 포스트와 함께 제대로 살펴보려고 한다. 다른 포스팅을 찾아주기 바란다.
(2) ftrace 디버깅 툴로 scheduling sequence와 priority 할당 확인
처음부터 보지 말고 parent가 생성된 이후 exec을 실행해서 어떻게 종료되는지까지를 보자.
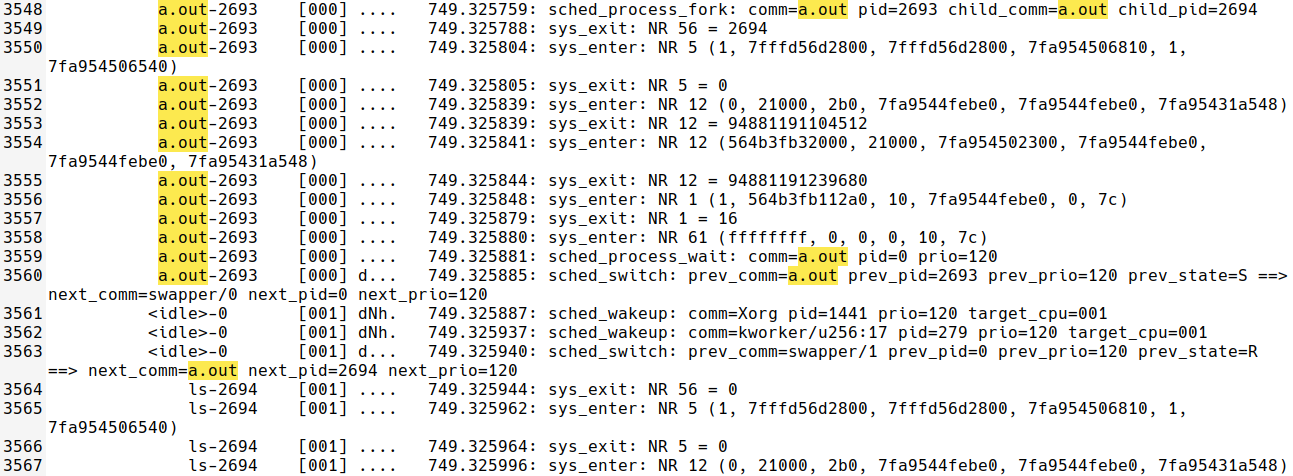
3548~3549: child process를 fork() 함수로 생성해준다.
3559~3560: wait() 함수를 호출해서 child의 exit를 기다린다. parent의 state가 S(Sleep) 상태로 전환된 뒤 child로 switching 된다.
3564~ : execlp() 함수에 의해 ls command가 실행되는 모습이 보인다.
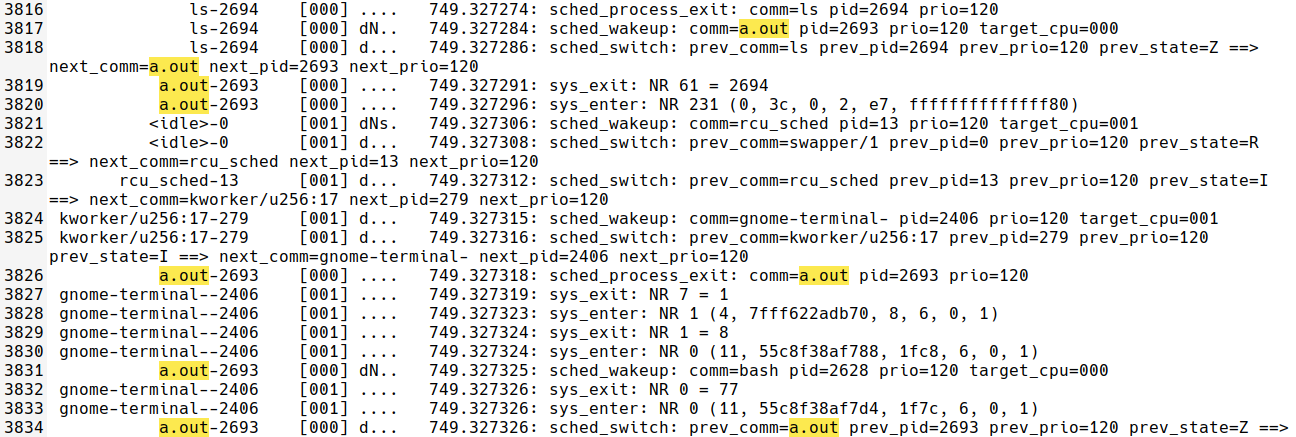
3816~3818: child의 ls가 exit 한다. 이후 parent를 깨우고 switch 된다.
3826~ : parent가 종료되고 zombie 상태가 된다. 이후 a.out parent인 bash에서 회수하는 과정을 거친다.
5. 실습 결과에 대한 정리 및 결론
조금 헷갈려서 왜 다른지에 대한 걸 구글링을 통해 어느 정도 정리하면서 이해하게 되었다. reference에도 적어놨지만 여기 링크를 참고해서 적은 것이다. 결론부터 말하자면 위에서 배운 fork() 호출 시 child에게 우선순위를 부여했던 건 UNIX 시절 또는 Linux Kernel v2.4 이전까지 사용했던 방법이다. 이유는 그 당시에는 Thread라는 개념 없이 process만을 생성하는 것이 일반적이었기 때문이다.
그러다가 Linux는 v2.2부터 fork() 함수에는 없는 task 간의 공유 리소스 관계를 결정할 clone() system call을 추가로 도입했고, 이후 v2.4부터는 multi-thread 환경을 지원하고자 clone() 함수의 옵션으로 CLONE_THREAD을 추가했다. 이 옵션을 통해 task_struct만을 복사해 thread를 생성할 수 있게 되었다.
하지만 여전히 user mode에서만 가능한 일이었다. 그렇지만 v2.6 부터는 NPTL(Native POSIX Thread Library)를 지원하여 kernel에서도 thread를 생성하는 게 가능해졌다.
결과적으로 내가 한 실험은 옛날 UNIX 및 linux가 가졌던 특징을 현대에도 똑같이 적용되고 있을 것이란 잘못된 생각으로 진행했던 것이다. 지금의 process or thread making은 내가 위에서 실험한 내용대로 진행된다는 것을 의미한다. 즉 parent든 child든 같은 priority를 갖고 같은 경쟁 상태로 들어가 실행되는 것을 확인할 수 있다.
Reference
https://gmlwjd9405.github.io/2018/09/14/process-vs-thread.html
https://en.wikipedia.org/wiki/Fork_(system_call)
https://en.wikipedia.org/wiki/Copy-on-write
http://redisgate.kr/redis/configuration/copy-on-write.php
https://iamyooon1.gitbooks.io/linux-kernel-core-with-vanilla/content/process_priority.html
https://hackmd.io/@sysprog/unix-fork-exec
https://man7.org/linux/man-pages/man2/clone.2.html
https://en.wikipedia.org/wiki/LinuxThreads
https://en.wikipedia.org/wiki/Native_POSIX_Thread_Library