![[Kernel of Linux] 5. Process Management (2)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Flovit%2Fbtrm5yHxpoV%2FAAAAAAAAAAAAAAAAAAAAAO6_FrLtRqSOKf_rwxzqKnhClpWnL1sCM0Cj_oLJhjsi%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1753973999%26allow_ip%3D%26allow_referer%3D%26signature%3DXkda1qL3PbOTR%252BI%252FVP1t6mB%252Fb%252BU%253D)
지난 강의 요약 - Process Management (1)
UNIX 시절에는 child를 만드는데 fork-exec 방식을 따랐다. 이 방식도 진화해왔었는데 처음에는 parent 측에서 먼저 wait() (혹은 종료) 할 때까지 기다렸다가 child가 실행되었다. 그 이후에는 parent의 page tables만을 복사하게 바뀌었지만 COW(Copy-on-Write)에 의해 page-fault가 많이 발생하여 비효율적인 오버헤드가 많이 생겼다. 그래서 이후에는 parent의 fork 호출 이후에 parent로 돌아가지 않고 child process의 우선순위를 높여줘서 child가 먼저 실행되도록 바꿨다.
위에서 기술한 옛날 UNIX가 사용하던 방식과는 달리 linux에서는 process를 task_struct를 기준으로 6개의 큰 구조체로 관리한다. 이후에는 fork()가 deprecated 한 system call이 되어서 clone() system call의 wrapper가 되었다. clone()으로 child가 복사할 구조체의 종류를 정해주는 것이 가능해짐으로써 thread라는 개념이 생겼고 다른 이름으로 LWP(Light-Weight Process)라고 불린다.
마지막으로 실험을 통해 현대의 linux kernel은 어떻게 처리하는지 직접 확인해봤는데 결과는 그냥 옛날 fork()의 동작 방식과 같았다. exec을 통한 COW가 일어나도 heap과 libc에서만 발생하였고, 나머지 section에서는 딱히 COW가 일어나지 않았다. 그렇기 때문에 COW로 인한 오버헤드가 많이 일어나는 상황이 발생할 수도 있다. 이를 UNIX에서 했던 방식인 fork() 이후 parent로 넘어가지 않고 child에서 바로 exec()를 호출하는 걸 구현한 library function이 존재한다. 바로 posiz_spawn() 함수다.
1. Kernel Thread

kernel thread란 결국엔 thread인데 기존에 배웠던 thread와의 차이점은 분명히 존재한다. kernel에서 clone() 호출에 의해 생성되었고, kernel's address space에 접근하고, kernel code를 실행한다. kernel space에서만 존재하고 몇몇 daemon이 이런 형태다.
1.1 Process State

process에는 state가 있다. 이 state를 보고 현재 이 process가 어떤 상태인지를 알 수 있게 해 준다.
- RUNNING
- INTERRUPTIBLE (wait)
- UNINTERRUPTIBLE (wait)
- ZOMBIE
- STOPPED
process는 영원히 cpu를 차지하고 있을 수 없기 때문에 특정 시간이나 순간이 오면 cpu를 반납하거나 뺏기게 되거나 종료가 될 수도 있다. 위의 리스트는 process가 가질 수 있는 상태를 나누어 놓은 것이다. 예를 들어 RUNNING 상태인 process가 I/O를 하기 위해서는 kernel에게 cpu를 뺏기게 되니 이때는 state가 WAIT 상태가 된다. 이후 I/O가 끝나면 process가 READY에서 기다리게 된다.
ZOMBIE 상태는 모든 리소스를 빼앗기고 PCB만 남은 상태를 가리킨다. PCB를 남기는 이유는 parent가 child가 무엇을 했는지 궁금할 수도 있다. 이걸 위해서 남겨둔 것이고 parent는 이를 확인한 후 없앤다.
2. Scheduling
2.1 Linux Scheduling Policy

리눅스에서는 가장 높은 priority(highest priority)를 가진 process가 가장 먼저 run 한다는 것은 배워서 아는 사실이다. 하지만 여기에 한 가지 더 봐야 할 조건이 있다. 바로 remaining timeslice다.

RR(Round-Robin) scheduler에서 사용하는 방식을 예로 들어보자. 어떤 process한테 100ms만큼 쓰고 내려오라고 했는데 미처 그 시간 동안 일을 다 처리하기도 전에 다른 process에게 선점당했다. 이후 선점했던 process의 사용이 끝나고 시간이 남았던 process가 다시 들어가려고 했지만 또 다른 priority가 높은 process에 의해 뒤로 밀렸다. 가능성은 낮은 얘기지만 이 process는 여러 많은 자신보다 높은 priority를 가진 processes에 의해 계속 기다리는 상황이 발생하기 시작한다.
이런 상황을 미연에 방지하기 위해 스케줄링할 때 priority 이외에 remaining timeslice도 고려해야 한다는 것을 알 수 있다.
2.2 Scheduling Algorithm

priority를 기준으로 ready queue를 만들 때 단순하게 생각하면 single linked list로 만들 수 있다. 하지만 이렇게 만들면 탐색 시간이 길어지니까 비효율적이다. 그래서 조금 더 탐색 시간을 줄이고 싶으면 high-low로 바꿀 수 있고 이걸 더 최적화시키면 priority 별로 나누어 관리할 수도 있다. 그리고 그림에는 나오지 않았지만 priority 별로 나눠놓은 ready queue에 더해서 그 priority list에 task가 존재하는지 표시해놓는 array를 추가로 만들어놓는다면 좀 더 빠른 탐색이 가능할 것이다.

방금 말했던 방식을 그린 도식이 위의 그림이다. bitmap[i]이 0이면 task 존재 X, 1이면 task 존재 O라는 뜻이다. list_head 구조체로 head를 가리키는 포인터를 가지게 한다. 두 개를 묶은 것이 바로 priority array다.

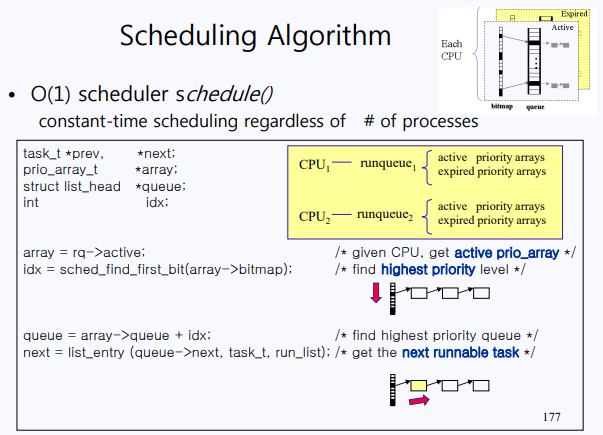
priority array를 따르는 cpu scheduler는 bitmap을 scan 하면서 NULL이 아닌 곳의 queue로 가서 task list를 traverse 하면 된다.
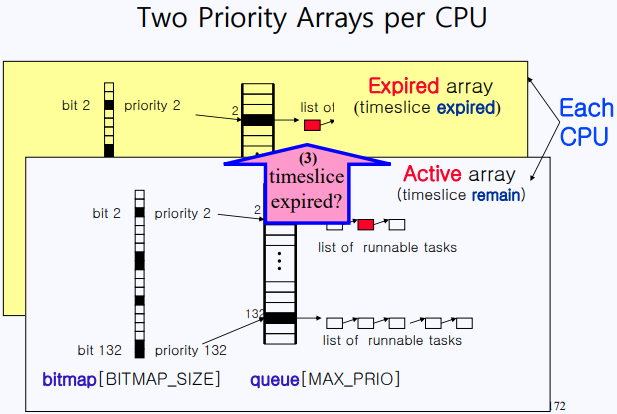

그런데 각 CPU에는 하나의 priority array만이 있는 게 아니라 2개가 있다. 하나는 아까 보았던 것이고 나머지는 timeslice를 다 써서 expired 한 process가 존재하는 priority array다. timeslice를 다 쓴 process는 expired array로 옮겨진다. 이런 식으로 동작하다 보면 언젠가는 active array에 process가 존재하지 않게 되고 이때 expired array에 존재하는 process에게 일률적으로 timeslice를 부여한다. 이는 active array와 expired array를 바꾼다는 의미이다. 이것이 바로 linux에서 말하는 O(1) scheduling이다.
3. Kernel Preemption

운영체제를 배우면 알아야 하는 개념 중 하나인 자원의 공유 문제가 있다. 하나의 리소스에 접근하는 두 개 이상의 process가 존재할 때 적절히 제어하지 않는다면 예상과는 전혀 다른 결과가 나올 수 있다는 것이다. 만약 다른 결과가 나왔다면 그건 데이터가 lost 된 것이고 이 문제를 lost update problem이라고 한다. 그래서 shared memory에 접근할 때는 mutual exclusion을 통해 interleaving을 방지해야 한다.
왜 갑자기 이걸 설명하느냐 하면 UNIX 시절에서는 우리가 아는 지식과는 다르게 처리를 했기 때문이다. 우리가 아는 건 mutex나 semaphore 같은 알고리즘을 통해 preemption이 있어도 lost update problem을 막을 수 있다는 사실이다. 하지만 UNIX에서는 이 문제를 상호 배제로 해결하지 않고 user mode가 아닌 (user는 각기 다른 address space를 가지고 있으니 신경 안 써도 된다) kernel mode에서 preemption을 막음(no preemption)으로써 해결하고 있었다. 하지만 이렇게 해결하는 방식에는 눈에 보이는 문제점이 있다. user mode면 괜찮지만 kernel mode에 있을 때에는 아무리 급한 task가 와도 preemption이 불가능하기 때문에 real-time에는 적합하지 않다는 단점이다. 이는 Andriod 같은 임베디드 시스템에는 적합하지 않다는 것이다. 그렇기 때문에 preemption이 필요한 것이다.

지금까지 배운 걸 정리하는 그림이다. sh, mail 두 프로그램이 돌고 있는 상황에서 kernel function을 호출하는 예를 들고 있다.
먼저 local variables에 접근하는 상황을 생각해보자. 결론부터 말하자면 이 접근은 아무런 문제가 없다. 이유는 단순히 각 process마다 각 kernel stack이 존재하므로 중간에 interrupt로 인해 cpu를 뺏기더라도 stack에 담긴 값은 private 하기 때문에 상관없는 것이다.
하지만 이번에는 kernel function 안에서 global variables에 접근하는 상황을 생각해보자. 이때는 lost update problem이 일어날 수 있는 상황이다. 이를 해결할 수 있는 방법은 운영체제에서 배웠듯이 해당 리소스에 lock을 걸면 간단히 해결된다.

그렇다면 kernel mode에서 cpu는 어떻게 preemption을 수행할까?
두 개의 variables를 보고 결정하게 된다. 먼저 preempt_count의 값이 0 인지 아닌지 체크한다. 0이라면 이 thread가 현재 critical section에 진입하지 않았다는 뜻이 되므로 preemption의 대상이 될 수 있다는 뜻이다. 또 하나의 variable은 바로 need_resched flag다. preempt_count가 0이 아닌 상태였다가 0으로 떨어진 상황을 가정한다. 이때 need_resched flag가 set 되어 있다면 현재 나보다 높은 priority를 가지는 process가 waiting 하고 있으므로 cpu를 그 process에게 양보해야 한다는 의미를 가진다.
'preempt_count == 0 && need_resched'가 true라면 이 thread는 preempt 될 수 있고 현재 다른 threads가 wait 중이다라고 해석할 수 있다.
3.1 The moment of kernel preemption

- kernel이 다시 선점 가능해지는 상황일 때
- 즉, unlock() 함수의 호출 이후
- "preempt_count == 0 && need_resched" 조건이 TRUE인 경우
- schedule() 함수를 호출 - interrupt handler가 끝난 후 kernel로 북귀할 때
- "preempt_count == 0 && need_resched" 조건이 TRUE인 경우
- schedule() 함수를 호출 - kernel에서 명시적으로 schedule() 함수를 호출할 때
- user mode로 복귀하려 할 때
- sleep 상태로 변경될 때

위에서 말한 조건 3가지를 도식화한 그림이다.