
Intro
「프로그래머가 몰랐던 멀티코어 CPU 이야기」(김민장 저)라는 책을 우연히 접하고 읽던 도중, 컴파일러 최적화 과정에서 발생 가능한 데이터/컨트롤/메모리 의존성에 대한 내용을 접하게 되었다. 의존성 분석을 통해 재배치(instruction reordering) 혹은 명령어 스케줄링(instruction scheduling) 최적화를 적용할 수 있다는 내용이다. 여기서 하나의 예시로 RAW(Read-After-Write; 무조건 순서대로 실행되어야 하는 의존성 관계) 상황에서의 메모리 로드를 들었다. 메모리 로드 이후 RAW 의존성을 갖는 명령어들이 줄줄이 있다면 캐시 미스를 일으킬 수 있는 메모리 로드를 먼저 앞쪽에서 처리하는 것이 효과적일 것이다.
하지만 싱글코어에서는 이 해결방법이 잘 통할지 몰라도 멀티코어에서의 메모리 로드/스토어는 CPU나 컴파일러가 이렇게 최적화한다면 프로그래머가 예측하지 못한 상황이 발생할 가능성이 높아진다. 그래서 이런 상황과 관련된 내용을 메모리 컨시스턴시 혹은 메모리 모델에서 찾을 수 있다며 추천한 글이 있다. 튜토리얼 형식의 글인데 필자는 이를 읽고 그 내용을 정리해보고자 한다.
* 자료 링크: https://www.hpl.hp.com/techreports/Compaq-DEC/WRL-95-7.pdf
Shared Memory Consistency Models: A Tutorial
- Sarita V. Adve, Kourosh Gharachorloo / September 1995
1. Introduction
공유 메모리나 단일 주소 공간 추상화는 싱글 프로세서로부터 더 자연스러운 전환을 제공하거나 데이터 파티셔닝, 동적 로드(load) 분산과 같은 어려운 프로그래밍 작업을 단순화시킴으로써 메시지 패싱 추상화 같은 몇 가지 이점을 제공해준다.
공유 메모리 프로그램에 정확하고 효율적으로 쓰기 위해서 프로그래머는 메모리가 멀티 프로세서에서 읽기와 쓰기가 어떻게 동작하는지에 대한 정확한 개념이 필요하다. 공유 메모리 프로그램의 일부인 Figure 1을 보자. 프로세서 1(앞으로 P1)은 테스크 레코드를 data 필드에 업데이트하면서 계속 그 레코드를 할당한다. 그러다 더 이상 남은 테스크가 없을 때, P1은 Head 포인터를 업데이트하는데 이 포인터는 가장 첫 번째 테스크 레코드를 가지는 테스크 큐를 가리킨다. 반면에 다른 프로세서들은 Head 포인터가 null이 아닐 때까지 기다리다가 크리티컬 섹션에 있는 Head가 가리키는 테스크를 가져오고(dequeue), 가져온 레코드의 데이터 필드를 최종적으로 접근한다. 프로그래머는 이 프로그램 코드 일부분으로부터 정확한 실행을 보장하려면 메모리 시스템으로부터 무엇을 예상해야 할까? 중요한 하나의 필요조건은 가져온 레코드의 data 필드로부터 읽어지는 값은 P1에서 기록된 레코드와 같아야 한다. 하지만, 많은 통상적인 공유 메모리 시스템에서는 프로세서들이 프로그래머의 예상과는 다른 결과를 이끌어내며 data 필드가 예전 값을 가지는 것이 관찰될 가능성이 있다.

공유 메모리 멀티 프로세서의 memory consistency model은 프로그래머가 예상한 결과와 시스템이 지원하는 결과 사이의 간극을 없애면서 메모리 시스템이 프로그래머에게 어떻게 보일 것인지에 대한 공식 사양을 제공한다. 실제로 이 consistency model은 공유 메모리 프로그램 실행 도중 읽혀서 리턴될 수 있는 값들에 제한을 둔다. 직관적으로는 읽기가 "마지막"으로 쓰인 같은 메모리 공간의 값을 리턴해야 한다. 유니 프로세서에서는 "마지막"이 프로그램 순서(program order - 예를 들어 프로그램 내에서 보이는 메모리 오퍼레이션 순서)에 의해 정확히 정의된다. 멀티 프로세서에서는 이게 적용되지 않는다. 예를 들어 Figure 1에서, 레코드 내의 data 필드 읽기/쓰기는 프로그램 순서와는 상관이 없는데 왜냐하면 두 개의 다른 프로세서에 상주하고 있기 때문이다. 이 모델은 sequential consistency라고 불린다. Figure 1의 프로그램에서 이 모델은 디큐된 레코드의 data 필드가 P1 프로세서가 쓴 새로운 값을 리턴함을 보장한다.
Sequential consistency는 간단하고 직관적인 프로그래밍 모델을 제공한다. 하지만 이는 유니 프로세서 안에서 공유 메모리 오퍼레이션 간에 엄격한 순서를 강제할 수 있는 많은 하드웨어와 컴파일러의 최적화를 불가능하게 만든다. 그렇기 때문에 수많은 relaxed memory consistency models가 Digital Alpah, SPARC V8, V9, IBM PowerPC와 같은 상업적으로 사용 가능한 아키텍처들의 지원을 받는 것들을 포함해서 제안되어왔다. 불행히도 (각 회사들의) 발간물에서 제안된 relaxed consistency models는 서로 미묘한 차이만이 존재했지만 이는 엄청난 다양성을 가져오는 중요한 요인이 되었다. 게다가 복잡하고 통일되지 않은 용어는 모델들을 이해하고 비교하기 어렵게 만들었다. 이 다양성과 복잡성 또한 relaxed memory consistency models(Figure 2 참고)에 대한 오해를 낳았다.

[튜토리얼 가이드의 목표]
- 대다수의 컴퓨터 전문가들에게 이해하기 쉬운 방향으로 sequential consistency와 relaxed memory consistency models에 대한 설명을 제공
- 간단하고 한결같은 전문 용어를 사용하는 다른 모델들의 시멘틱(코드 조각의 의미)을 묘사
- 하드웨어 기반의 공유 메모리 시스템을 제안하는 consistency model에 집중해서 볼 것임
- 시스템 중심, 프로그래머 중심 관점을 같이 아우르는 설명
이것만으로는 처음 consistency model을 접하는 독자가 "그래서 sequential consistency, relaxed consistency가 뭔데?"라고 의문을 가질 수 있다. 그래서 간단하게 다음 링크의 글을 토대로 정리하여 이해하고 넘어가고자 한다.
멀티 프로세서 환경(distributed system)에서 우리는 병렬 처리를 통해 빠른 결과를 얻고자 하는 것을 목표로 한다. 하지만 어떤 두 물리 코어(프로세서)가 공유 메모리 상의 자원을 read/write 하고자 한다면 반드시 synchronization을 해야 한다. Synchronization을 통해 공유 데이터의 consistency를 유지할 수 있다. 이때 consistency를 유지한다는 것은 공유 데이터를 read 할 때, 최근 과거에 쓰인 최신 데이터를 읽는다는 것을 의미한다. Consistency는 보장 정도에 따라 두 가지로 나뉜다.
[ Strict Consistency / Non-Strict Consistency ]
[ Strict Consistency ]
항상 과거에 쓰인 최신 데이터를 읽을 수 있음. 아래 두 가지 조건 중 하나를 만족해야만 가능.
1. distributed system에는 global clock 존재. 각 코어들은 이 clock에 완벽히 동기화된 상태.
- global clock 기준 write operation 다음 사이클에 read operation 함 (operation 직렬화)
- 단, write operation은 read operation 이전에 이루어져야 함
2. write가 즉시(빛의 속도로) 이루어져야 함.
즉 이론적으로는 consistency model이지만 물리적 한계로 인해 사실상 불가능한 모델.
[ Non-Strict Consistency ] - Sequential & Relaxed Consistency
< Sequential Consistency > - Figure 3 참고
Strict Consistency의 global clock과 같은 물리적으로 불가능한 조건 대신 아래의 물리적으로 가능한 조건을 내세움.
- Operation의 ordering 유지
- Atomic read/write operation
공유 데이터 접근 시 single operation queue가 있어 순차적으로 들어온 read/write operations이 존재한다. Strict consistency보다는 좋은 성능을 보이지만 현재 실행 중인 operation이 끝날 때까지는 다른 operations는 무조건 대기해야만 한다는 단점이 있다. 각 operation은 순서대로 진행되고 atomic 하다.
< Relaxed Consistency >
만족스럽지 않은 sequential consistency을 해결하려 우리는 sequential consistency의 조건인 ordering 혹은 atomic write operation을 깨고자 한다.
1. Ordering 깨는 법
- Write to Read: Previous write가 끝나기 전 read이 수행될 수 있다.
- Write to Write: Previous write가 끝나기 전 write이 수행될 수 있다.
- Read to Read or Write: Previous read가 끝나기 전 read 또는 write를 수행할 수 있다.
2. Write Atomicity 깨는 법
- Read others' write data early
(위의 깨는 법들에 대한 자세한 내용은 링크 내 글 참고!! 꼭 읽어보시길 추천드립니다.)
세 줄로 정리하자면, distributed system과 같은 멀티 프로세서 환경에서 필요한 synchronization을 통해 데이터의 consistency를 유지해야 한다. Consistency 보장 정도에 따라 strict/non-strict consistency로 나뉘는데 현실적으로 가능한 조건을 가진 것은 non-strict 쪽이며 종류는 sequential/relaxed consistency가 있다. 성능은 relaxed consistency 쪽이 더 좋다.
이제 위 챕터 1의 글을 다시 읽어보면 이해가지 않던 부분들이 이해될 것이다.
2. Memory Consistency Models - Who Should Care?
프로그래머와 시스템 사이의 인터페이스 관점에서 memory consistency의 효과는 공유 메모리 시스템에 퍼져있다. 이 모델은 프로그래밍 가능함(programmablity)에 영향을 미치는데 왜냐하면 프로그래머들은 프로그램의 정확성에 대해 추론하기 위해 이 모델을 사용해야만 하기 때문이다. 이 모델은 시스템의 성능에도 영향을 미치는데 하드웨어와 시스템 소프트웨어에 의해 착취당하는 최적화 유형을 결정하기 때문이다. 마지막으로 하나의 모델에서의 일치 부족으로 인해 다른 모델을 지원하는 시스템 간 소프트웨어를 이동시킬 때 이식성(portability)이 영향을 받을 수 있다.
Memory consistency model의 사양은 인터페이스가 프로그래머와 시스템 사이에서 정의되는 모든 레벨을 필요로 한다. 기계어 코드 인터페이스에서는 memory consistency model은 기계어 코드를 작성하거나 추론하는 기계어 하드웨어 디자이너와 프로그래머들에 영향을 끼친다. 고수준 언어 인터페이스에서는 이 사양이 고수준 언어를 사용하는 프로그래머들과 고수준 언어의 코드를 기계어로 바꾸는 소프트웨어와 이 코드를 실행하는 하드웨어의 디자이너들에게 영향을 준다. 그러므로, programmabillity, performance, 그리고 portability에 대한 우려는 여러 가지 레벨로 존재할 수 있다.
요약하자면, memory model은 프로그래머의 관점에서 본 병렬 프로그램 작성과 시스템 디자이너 관점에서 본 병렬 시스템(프로세서, 메모리 시스템, 상호 연결된 네트워크, 컴파일러, 프로그래밍 언어들을 포함) 디자인에서의 사실상 거의 모든 측면에 영향을 미친다.
3. Memory Semantics in Uniprocessor Systems (단일 프로세서 기준!)
대부분의 고수준 유니 프로세서 언어들은 메모리 연산을 위한 간단한 sequential semantics를 제공한다. 이 semantics는 프로그래머가 모든 메모리 연산이 프로그램에 의해 특정된 연속적인 순서 안에서 딱 한 번 일어날 것이라 추정할 수 있게 한다. 그래서 프로그래머는 read가 연속적인 프로그램 순서로 인해 read 이전에 같은 자리의 마지막 write의 값을 반환할 것이라 예측한다. 다행히도, 연속성의 환상은 효율적으로 지원될 수 있다. 예를 들면 유니 프로세서 데이터를 유지하고 의존성을 컨트롤하는 것만으로 충분하다 (두 오퍼레이션이 같은 위치에 있거나 한쪽이 다른 쪽의 실행을 컨트롤할 때 프로그램의 순서대로 실행하기). 유니 프로세서의 데이터와 의존성 제어가 존경받는 한(보장되는 한), 컴파일러와 하드웨어는 자유롭게 오퍼레이션들을 다른 위치로 재 정렬할 수 있다. 이는 레지스터 할당, 코드 모션, 반복문 변환과 같은 컴파일러 최적화와 파이프라이닝, 다중 이슈, 쓰기 버퍼 우회와 전달, lockup-free caches, 메모리 오퍼레이션들의 오버레핑과 재배치를 유발하는 모든 것들과 같은 하드웨어 최적화를 가능케 한다. 전반적으로 단일 프로세서들의 sequential semantics는 프로그래머에게 간단하면서도 직관적인 모델을 제공하지만 효율적인 시스템 디자인의 넓은 범위를 포함하지는 않는다.
단일 프로세서 환경에서는 프로그래머가 메모리 연산들이 순서대로 실행될 것이라 예측한다. 결과는 그런 것처럼 보이게 나오지만 실제로는 최적화 등의 이유로 메모리 연산의 순서가 재 정렬될 수 있다. 단일 프로세서 환경에서는 단일 프로세서 내의 데이터를 유지하고 의존성을 제어하는 것이 가능하기만 하면 여러 최적화 방법을 통해 연속성의 환상을 프로그래머에게 심어줄 수 있다.

4. Understanding Sequential Consistency
공유 메모리 멀티 프로세서를 위한 가장 일반적으로 가정되는 memory consistency model은 sequential consistency다 - 레퍼런스 [16]에 따르면 Lamport에 의해 공식적으로 정의되었다.
Definition: [멀티 프로세서 시스템이 순차적으로 일관성이 있는 경우] 실행 결과가 마치 모든 프로세서의 연산이 어떤 순차적인 순서로 실행되고 각 개별 프로세서의 연산이 프로그램에서 지정한 순서 안에서 그 절차 안에서 나타나는 것과 같다.
Sequential consistency에 대한 두 가지 관점: (1) 개별 프로세서들의 연산 간의 프로그램 순서가 유지됨, (2) 모든 프로세서들의 연산이 하나의 순차적인 순서로 유지됨 (= 각 프로세서 안에서만 연산 순서가 유지되느냐, 아니면 전체 프로세서가 하나의 큰 연산 순서를 유지하느냐). 후자의 관점(전체가 순서 유지)은 하나의 메모리 연산이 다른 메모리 연산들에 대해 원자적이거나(atomically) 순간적으로(instantaneously) 실행되는 것처럼 보이게 한다.
Sequential consistency는 Figure 3에 나타난 것처럼 프로그래머에게 시스템에 대한 간단한 시각을 제공한다. 개념적으로는 하나의 글로벌 메모리와 각 타임 스텝에서 임의의 프로세서에게 메모리를 연결하는 스위치가 존재한다. 각 프로세서는 프로그램 순서대로 메모리 연산을 수행하고 스위치는 모든 메모리 연산 사이의 전역 직렬화(global serialization)를 제공한다.

Figure 4는 sequential consistency의 semantics를 묘사하기 위해 두 가지 예시를 들고 있다. (a)는 단일 프로세서의 연산 사이의 프로그램 순서의 중요성을 나타낸다. 이 코드는 크리티컬 섹션을 위한 Dekker의 알고리즘의 구현(두 프로세서 P1, P2, 그리고 0으로 초기화되는 두 플래그 Flag1, Flag2)을 나타낸다. (b)는 메모리 오퍼레이션의 atomic execution을 강조하고 있다. 3개의 프로세서가 0으로 초기화된 A, B공유 변수를 공유하고 있다. Sequential consistency의 원자성(atomicity) 측면은 위 실행에서 P1의 write 효과가 전체 시스템에서 동시에 보이는 것처럼 추측할 수 있게 만든다. 그래서 P3는 위 실행을 통한 P1의 write 효과가 보이도록 보장하고 A의 값을 읽어 반드시 1의 값을 반환해야 한다.
Figure 3에서 소개한 직관적인 추상화를 실제 시스템에서는 어떻게 구현하는지 알아본다. 단일 프로세서와는 달리 멀티 프로세서에서는 seqeuntial consistency를 유지하기 위해 지역 기반(per-location basis; 각 프로세서 기반)에서만 메모리 순서를 유지하는 것만으로는 부족하다.
Sequential consistency에 대한 개념을 소개하고 바라볼 수 있는 두 가지 관점을 두 가지 예제를 기준으로 설명했다. 각 관점에 대해 정리하자면, (a) 순차적 실행을 보장하기 위해 공유 flag를 통해 프로세서들이 서로 상태를 보면서 개별 메모리 오퍼레이션의 순서를 지키거나 (b) 원자성을 가진 메모리 오퍼레이션을 통해 프로세서들이 다 같이 순서를 지키는 방법을 쓸 수 있다는 것이다.
5. Implementing Sequential Consistency
일반적인 하드웨어 최적화를 이용해 sequential consistency를 다루는 것부터 시작한다. 프로그램 순서와 원자성의 문제로부터 분리하기 위해, 먼저 캐시가 없는 환경에서의 sequential consistency를 보고 다음으로 캐시 한 공유 데이터의 효과를 고려할 것이다. 이 섹션의 마지막 파트에서는 일반적인 컴파일러 최적화를 이용한 sequential consistency를 살펴볼 것이다.
5.1 Architectures Without Caches
[데이터 캐싱이 없는 상태에서 sequential consistency를 구현할 때 발생하는 전통적인 상호작용으로써의 하드웨어 최적화 3가지 방법]이 있다. 캐시가 없는 환경에서 sequential consistency를 정확히 구현하기 위해 중요한 요소는 각 프로세서의 오퍼레이션으로부터의 프로그램 순서를 유지하는 것이다. Figure 5에서 보이는 t1, t2, t3,... 는 메모리에서의 메모리 오퍼레이션 순서와 일치한다.
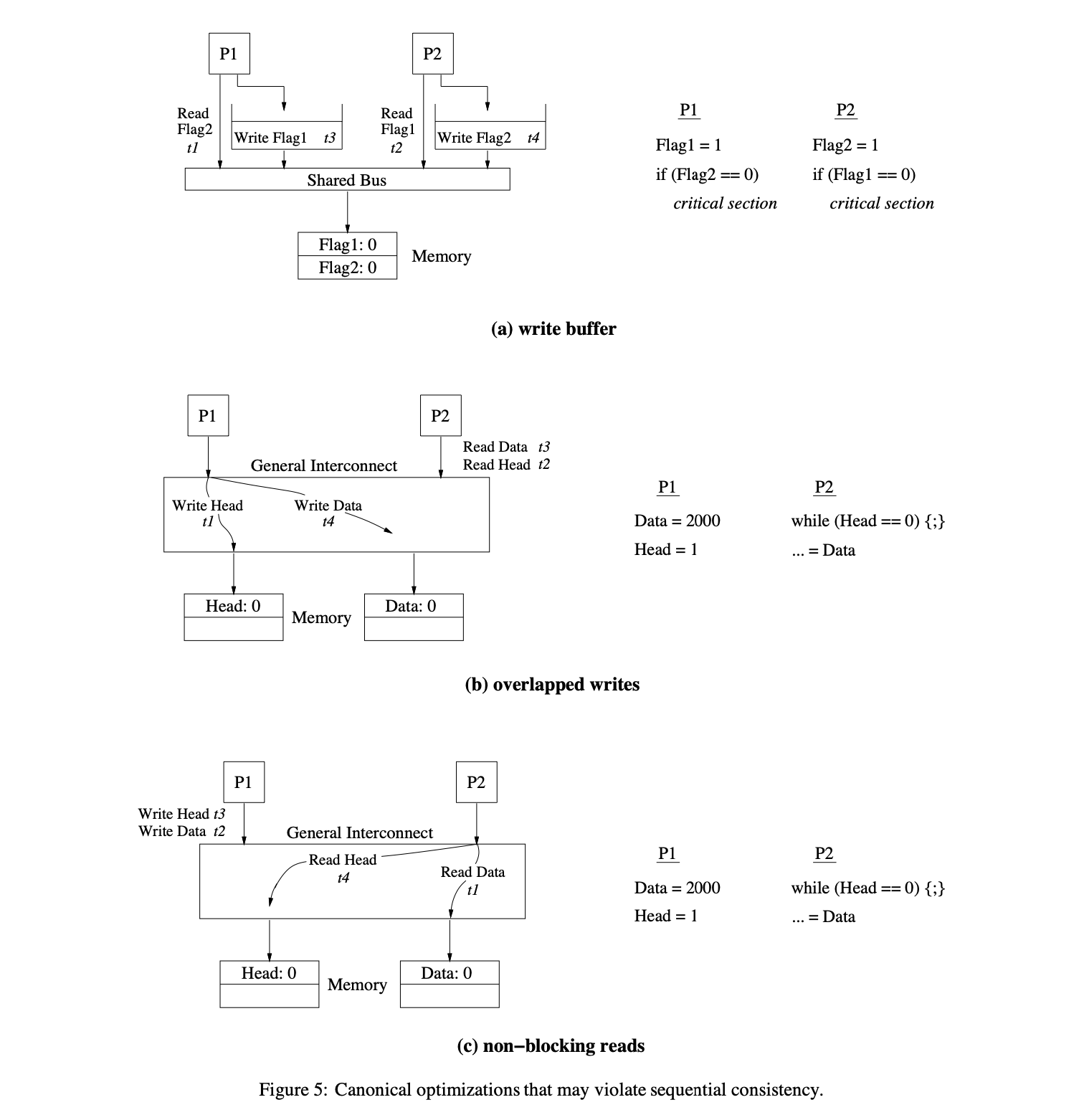
5.1.1 Write Buffers with Bypassing Capability
첫 번째 예시는 read 이후의 write 사이의 프로그램 순서를 유지하는 것의 중요성에 대해 살펴볼 것이다. Figure 5(a)는 캐시가 없는 bus-based 공유 메모리 시스템에 대한 예시다. 프로그램 순서에 따라 한 번에 하나의 메모리 오퍼레이션을 실행하는 하나의 간단한 프로세서를 가정한다. 고려할 유일한 최적화는 우회 능력이 있는 write buffer를 사용하는 것이다. Write 할 때, 한 프로세서는 간단히 write buffer에 write 오퍼레이션을 넣고 쓰기가 완료될 때까지 기다리지 않고 계속 진행한다. 그 이후의 read는 빠른 완료를 위해 write buffer 안에 있는 이전의 write들을 우회하는 게 가능하다. 이 우회는 읽히는 주소가 버퍼 된 어떠한 write들의 주소와 일치하지 않는 한 허용된다. 위 방법은 단일 프로세서에서 write 오퍼레이션의 지연(latency)을 효과적으로 숨기는 일반적인 하드웨어 최적화 중 하나다.
Write buffer의 사용이 sequential consistency를 망칠 수 있는 방법은 Figure 5(a)의 프로그램을 보면 된다. 4(a)에서도 봤던 Dekker 알고리즘이다. 현실에서는 이론적으로 나온 결과와는 다르다. 각 프로세서는 write를 저장하고 write buffer의 write를 이후의 read들이 우회할 수 있다. 그래서 P1, P2 양쪽에서의 read는 write가 되기 전에 메모리 시스템으로부터 실행될 수 있다는 뜻이므로 read 시 서로의 flag로부터 0을 읽을 수도 있다는 것이다.
이러한 상황은 sequential consistency를 망치고, P1과 P2가 같은 타이밍에 critical section에 진입할 가능성을 만들게 된다.
위와 같은 최적화는 (다른 위치에 있는 오퍼레이션들 간의) 우회가 단일 프로세서의 데이터 의존성을 해치지 않기 때문에 전통적인 단일 프로세서 안에서는 안전하다. 하지만 예시에서 살펴봤듯이, 이런 종류의 재배치는 멀티 프로세서 환경에서 sequential consistency semantics를 쉽게 위반할 수 있다.
5.1.2 Overlapping Write Operations
두 번째 최적화는 두 write 오퍼레이션 간의 프로그램 순서를 유지하는 것의 중요성에 대해 설명한다. Figure 5(b)는 일반적인 (non-bus) 상호 연결 네트워크와 다중 메모리 모듈을 가진 시스템이다. 일반적인 상호 연결 네트워크는 bus 기반 디자인에서 직렬화 병목 현상을 줄여주고 다중 메모리 모듈은 동시에 다중 오퍼레이션을 지원할 수 있다. 여전히 프로세서들은 프로그램 순서대로 메모리 연산을 실행하고 전 write 연산이 끝날 때까지 기다리지 않고 그 이후의 연산을 진행하는 상황을 가정한다. 이전 예제와의 중요한 차이점은 같은 프로세서에서 실행되는 다중 write 연산들이 동시에 다른 메모리 모듈로부터 서비스될 수도 있다는 것이다.
Figure 5(b)의 예제 프로그램은 위의 최적화가 어떻게 sequential consistency를 해치는지 보여준다; Figure 1에서 봤던 예제를 간략화시킨 버전이다. 순서 일치 시스템(sequentially consistent system)은 P2에서의 Data 읽기가 P1이 쓴 값을 반환할 것이라는 점을 보장한다. 하지만, (b)에 나온 시스템처럼 P1에서의 write에 오버래핑(겹침)을 허용하는 것은 쉽게 이 보장을 위반한다. Data와 Head 변수는 다른 메모리 모듈에 상주하고 있다. Head로의 write가 네트워크 상에서 Data로의 write가 Data가 들어있는 메모리 모듈에 도착하기 이전에 삽입될 수 있기 때문에, 두 write는 완전히 프로그램 순서에서 벗어날 가능성이 있다. 그러므로, 또 다른 프로세서는 Head의 새 값을 발견하지만 오래된 Data 값을 얻을 가능성이 있다. Write buffer 안에 같은 캐시 라인으로의 coalescing write와 같은 다른 일반적인 최적화들 또한 비슷한 write 연산들의 재 정렬을 야기할 수 있다.
다시 말하자면, write를 다른 위치로의 재 정렬을 허용하는 것은 단일 프로세서 프로그램에서는 안전한 반면에, 위의 예제와 같은 경우에는 그러한 재 정렬이 쉽게 sequential consistency의 semantics를 위반한다는 것을 보여준다. 이런 문제점을 없애는 한 가지 방법으로는 같은 프로세서에서의 다음 write 연산이 네트워크 안에서 삽입되기 전에 현재의 write 연산이 해당 연산이 속한 메모리 모듈에 도착하기를 기다리는 것이다. 일반적으로 위의 순서를 강제하는 것은 실행 중인 프로세서에게 write가 타깃에게 도착했다는 것을 알리기 위한 acknowledgement response을 필요로 한다. 이 acknowledgement response는 일반 상호 연결 네트워크 상의 시스템 내의 write 이후에 이루어지는 read의 프로그램 순서를 유지하는 데에도 유용하다.
bus가 존재하지 않고 여러 메모리 모듈이 존재하는 멀티 프로세서 환경에서는 각 메모리 모듈은 서로의 consistency에 대해서는 보장되지 않으므로 write 작업의 순서 또한 보장되지 않는다. 이는 다른 write의 연산 종료 상황을 알 수 없기 때문에 발생하는 것이다.
여기서 오퍼 래핑(overlapping)이라는 단어는 말 그대로 순서를 지키지 않고 다른 순서와 겹치는 경우를 말한다.
5.1.3 Non-Blocking Read Operations
세 번째 최적화는 read or write 이후의 read 순서를 유지하는 것의 중요성에 대한 것이다. Non-blocking read를 지원하는 시스템 Figure 5(b)와 반복해서 Figure 5(c)를 고려해보자. 대부분의 초기 RISC 프로세서들은 read 작업(예를 들어 blocking read)의 반환 값에 대해 지연하는 반면, 많은 최근의, 그리고 차세대 프로세서들은 non-blocking (lockup-free) 캐시들, 추측 실행(speculative execution), 동적 스케줄링 등의 기술들을 사용함으로써 read 작업을 선행하는 기능을 가지고 있다.
Figure 5(c)는 같은 프로세서 내의 read 덮어쓰기가 어떻게 sequential consistency를 위반할 수 있는지를 보여주는 예시다. 이 프로그램은 이전 최적화에서 사용된 것과 같은 것이다. P1은 P1의 write가 각각의 메모리 모듈에 프로그램 순서대로 도착할 것이라 확신하는 상황이라 가정하자 (그러니까 적어도 5.1.2에서의 overlapping write가 일어나지 않고 정상적으로 write 된 상태라고 가정). 그럼에도 불구하고, 만약 P2의 read 작업들이 overlap 된 방법으로 실행하는 게 가능하다면, (P2의) Head 읽기는 P1에서 Head의 쓰기 이후에 해당 메모리 모듈에 도착하는 반면에 (P2의) Data 읽기는 P1에서 Data에 쓰기 전에 해당 메모리 모듈에 도착할 가능성이 존재한다 (언밸런스한 각 메모리 모듈로의 접근); non-sequentillay-consistent 결과가 나올 수 있다. 쓰기 작업 이후의 읽기 overlapping 또한 위와 유사한 (5.1.2와 유사한) 문제점을 나타낼 수 있다; 하지만, 후자의 이 최적화는 최근 프로세서에서는 보통 쓰이지 않는다.
여기서는 write의 순서는 지켜진 상황이더라도 read 하려는 다른 프로세서 쪽에서 non-blocking read로 인해 이번에는 read 작업들이 오버래핑되는 상황이 발생한 경우다.
5.2 Architectures With Caches
이전 section에서는 캐시가 없는 sequential consistency model의 구현 시 메모리 오퍼레이션의 재정렬로 인해 일어나는 복잡성들에 대해 말했다. 공유 데이터의 캐싱(혹은 복제)은 sequential consistency를 위반하는 비슷한 재정렬 행위를 제공할 수 있다. 예를 들어, 캐시로부터의 첫 번째 레벨 write는 우회 기능을 가진 write buffer로부터 허용되는 것과 비슷한 재정렬을 야기할 수 있는데, 그 이유는 프로그램 순서 안에서 write 이후에 오는 read가 write 종료 전에 캐시로부터 서비스될 수도 있기 때문이다. 그러므로 캐시와 함께 하는 구현은 반드시 각 프로세서의 오퍼레이션이 프로그램 순서로 실행된다는 환상을 유지하기 위한 예방책(precautions) 또한 가져야 한다. 가장 주목해야 할 점으로는, 프로세서의 read가 그 프로세서의 캐시에 접근할지라도, 그 프로세서는 일반적으로 프로그램 순서에 따른 이전 작업들이 끝날 때까지는 캐시 된 값을 읽을 수 없다.
공유 데이터의 복제는 세 가지 추가적인 이슈가 있다. 1) 다수의 복사본들의 존재는 새롭게 쓰인 값을 변형된 위치의 모든 캐시된 복사본들에게 전파하기 위해 보통 cache coherence protocol로 불리는 메커니즘을 필요로 한다. 2) (write와 이후의 오퍼레이션들 사이의 프로그램 순서를 유지하기 위해) write가 완료됨을 감지하는 것은 복제본의 존재 안에서 더 많은 트랜잭션을 필요로 한다. 3) 다수의 복사본들에게 변화점을 전파하는 것은 본질적으로 non-atomic operation인데, 이는 다른 오퍼레이션들의 관점에서 봤을 때 write의 원자성 환상(illusion of atomicity)을 유지하는 것을 더 어렵게 만드는 것이다. 우리는 세 가지 각 이슈들에 대해 아래에서 더 자세히 다룰 것이다.
5.2.1 Cache Coherence and Sequential Consistency
캐시 일관성(cache coherence, or cache consistency)에 대한 몇 가지 정의들은 literature(문학? 인쇄물?)에 존재한다. 가장 강력한 정의들은 사실상 sequential consistency의 동의어로 취급한다. 다른 정의들은 극단적인 relaxed ordering의 보장(guarantees)라고 본다. 특히, 일반적으로 cache coherence protocol과 연관된 하나의 조건들의 집합으로 다음과 같은 것들이 있다: (1) write는 결국 모든 프로세서들에게 보이게 된다, 그리고 (2) 같은 위치에서의 write들은 모든 프로세서들에 의해 같은 순서로 있는 것처럼 보일 수 있다 (같은 위치에서의 write들의 직렬화로도 언급됨)[13]. 위의 조건들은 후자의 조건(2번)이 모든 프로세서들에게 같은 순서로 진행되는 것처럼 보이기 위해서는 (같은 위치뿐만이 아닌) 모든 위치에 write 하는 것이 필요하고, 또 명백하게 단일 프로세서의 오퍼레이션들이 프로그램 순서 안에서 실행하는 것처럼 보일 필요가 있기 때문에 sequential consistency를 만족시키기에 완벽히 충분하지 않다.
우리는 어떠한 것이 consistency model이라고 해서 캐시 일관성이라는 단어를 사용하지 않는다. 대신, 새롭게 쓰인 값을 변형된 위치에 있는 캐시된 복사본들에게 전파하는 메커니즘의 관점에서 간단하게 캐시 일관성 프로토콜을 살펴본다. 값의 전파는 일반적으로 사본을 무효화하거나(또는 제거하거나) 사본에 새롭게 쓰인 값을 업데이트해줌으로써 보관된다. 이러한 캐시 일관성 프로토콜 관점에서 봤을 때, memory consistency model은 새로운 값이 주어진 어떠한 프로세서에게 전파될 수 있을 경우 초기, 후기 바운드(경계)를 제공하는 정책으로서 해석될 수 있다.
Cache coherence의 정의를 살펴보고, 이와 sequential consistency 간의 관계를 정의하고자 했다. Cache coherence 프로토콜의 조건을 만족시키더라도 여전히 sequential consistency를 만족한다고는 볼 수 없다.
5.2.2 Detecting the Completion of Write Operations
이전 섹션에서 언급했듯이, write부터 이후의 오퍼레이션까지의 프로그램 순서를 유지하는 것은 일반적으로 write의 종료를 알리는 acknowledgement response가 필요하다. 캐시가 없는 시스템에서는 acknowledgement respons가 목표 메모리 모듈에 write 오퍼레이션이 도착하자마자 생성될지도 모른다. 하지만, 위의 경우는 캐시가 있는 디자인에선 충분하지 않을지도 모른다. Figure 5(b)의 코드와, 앞과 같은 모양으로 묘사되지만 각 프로세서에 캐시를 통해 write를 하도록 하는 향상된 코드를 가지는 비슷한 시스템을 고려해보자. 프로세서 P2는 해당 프로세서의 캐시에서 Data를 처음에 가진다고 가정하자. P1은 P1의 Head에 쓰려고 하는데, 상황을 보면 선행된 Data로의 쓰기가 목표 메모리에 도착한 이후지만 아직 P2로는 그 값(Data 쓰기)이 (무효화나 업데이트 메시지를 통해) 전파되기 전이라고 가정한다 (간단히 말해 Data -> Head 쓰기 순서로 진행되는 중(두 값은 공유 메모리에 상주하는 공유 데이터들). P1 관점에서는 Data로의 쓰기는 완료돼서 이제 Head에 쓰려는 중인데, 아직 P2는 Data가 새 값으로 바뀌었다는 상황을 모른다. P2의 캐시로의 쓰기 전파가 일어나지 않았기 때문.). 이건 P2가 Head의 새 값을 읽지만 여전히 P2 캐시의 오래된 Data 값을 반환할 가능성이 있다. 이건 sequential consistency를 위반한 것이다. 이 문제는 P1이 Head에 write를 진행하기 전에 P2 캐시에서의 Data 사본을 업데이트되거나 무효화되기를 기다린다면 회피 가능해진다.
그러므로, 다른 프로세서 캐시들에 복사된 줄에 쓸 때엔, 시스템이 일반적으로 목표 캐시들로부터 무효화나 업데이트 메시지의 수신을 확인하는 메커니즘을 필요로 한다 (한마디로 무언가에 변화(write 오퍼레이션과 같은 변화)의 적용 결과를 전파받아야 한다는 것). 게다가, acknowledgement messages는 (메모리나 write를 실행하는 프로세서 둘 중 하나에서) 수집될 필요가 있고, write를 실행하는 프로세서는 쓰기 완료를 통보해야 한다. 프로세서는 위의 통보 이후에만 write가 완료된 것으로 간주할 수 있다. 일반적인 최적화는 처리하고 있는 노드로부터 받는 즉시, 그리고 잠재적으로 실제 캐시 복사본이 영향을 받기 전에 무효화 또는 업데이트 메시지를 확인하는 것이다; 이런 디자인은 특정 순서 제약들이 캐시로 들어오는 메시지들을 처리할 때 관찰되는 한 sequential consistency를 여전히 만족시킬 수 있다 [6].
Sequential consistency를 유지하기 위해 write의 종료를 알리고 이를 확인하는 메커니즘이 필요하다. 알리는 과정은 acknowledgement messages를 통해, 확인하는 과정은 시스템의 각 프로세서가 그러한 통보를 확인하도록 디자인하는 것을 통해 sequential consistency는 만족된다.
5.2.3 Maintaining the Illusion of Atomicity for Writes

Sequential consistency가 메모리 작업이 원자적이거나 즉각적으로 나타나길 원하는 반면에, 여러 캐시 복사본들에 변경점들을 전파하는 것은 본질적으로 non-atomic 작업이다. 우리는 데이터 복제가 있는 상태에서 원자성의 출현을 보장하는 두 가지 조건에 동기를 부여하고 설명한다. 비원자성(non-atomicity)으로 인한 문제들은 업데이트 기반 프로토콜을 통해 설명하기 쉬워진다; 그러므로, 앞으로 볼 예제들은 그런 프로토콜을 가정한다.
첫 번째 조건에 동기를 부여하기 위해 Figure 6에 나타나는 예제를 고려해보자. 모든 프로세서들은 프로그램 순서에 따라, 그리고 한 번에 하나씩 메모리 오퍼레이션을 실행한다고 가정한다. 만약 프로세서 P1, P2에 의해 A로의 쓰기를 위한 업데이트가 프로세서 P3, P4에 다른 순서로 도달한다면, sequential consistency를 위반할 가능성이 있다. 그러므로, 프로세서 P3, P4는 A에 쓰기가 비 원자적인 것처럼 보이게 만들면서 각각의 A 읽기가 다른 값을 반환할 수 있다 (예를 들어, register1과 register2가 1과 2라는 값을 각자 할당받을 수 있다). Sequential consistency의 위와 같은 위반은 메시지들이 네트워크 내에서 다른 경로를 통해 여행하고 도착 순서에 대해 아무런 보장이 없는 (Figure 5(b) 예시와 같이) 일반적인 상호 연결 네트워크를 사용하는 시스템에서 가능하다. 이 위반은 동일한 위치에 쓰기가 직렬화되도록 하는 조건을 부여하면 피할 수 있다; 예로써 모든 프로세서가 같은 위치에서의 쓰기는 같은 순서로 보인다. 이러한 직렬화는 주어진 위치에서의 모든 업데이트나 무효화가 한 곳(예시. 디렉터리)에서부터 유래하고 주어진 source와 destination 간의 그러한 메시지들의 순서가 네트워크에 의해 보존된다면 저장될 수 있다. 하나의 대안은 동일한 위치의 이전 쓰기를 대표해서 발생된 어떠한 업데이트나 무효화가 승인될 때까지 업데이트나 무효화를 지연하는 것이다 (간단히 정리하자면, 현재의 쓰기로 인해 발생한 업데이트 또는 무효화 메시지를 이전에 발생한 쓰기 때문에 발생한 업데이트 또는 무효화 메시지가 모두 승인되어 없어질 때까지 기다렸다가 적용시키자는 것이다).
두 번째 조건에 동기를 부여하기 위해 Figure 4(b)에서의 프로그램 일부분을 업데이트 프로토콜과 함께 다시 고려해보자. 모든 변수는 처음에 모든 프로세서에 캐시되어 있다고 가정한다. 더해서, 모든 프로세서는 메모리 오퍼레이션을 프로그램 순서에 따라, 그리고 한 번에 하나씩 실행하고 (위에서 설명한 대로 acknowledgements를 기다리면서), 동일한 위치에서의 쓰기는 직렬화된다고 가정한다. 이건 일반적인 네트워크를 사용하는 시스템에서 sequential consistency를 여전히 위반할 수 있다; 조건들 - (1) 프로세서 P2가 A의 업데이트가 프로세서 P3에 도착하기 전에 A의 새 값을 읽고, (2) P2의 B 업데이트가 (P3 기준으로) A의 업데이트 이전에 P3에 도착하고, (3) P3가 B의 새 값을 읽은 다음 (아직 P1에서 A의 업데이트 메시지를 받기 전에) 자신의 캐시에 있는 A의 값을 읽으려 한다 (한마디로 A 값이 업데이트되었다는 메시지를 P3가 받기도 전에 if(B==1)의 조건을 만족시켜 자신의 캐시에 있던 아직 업데이트되지 않은 값을 읽게 된다는 것이다). 그러므로, P2와 P3는 쓰기가 비 원자적인 것처럼 보이게 만들면서 다른 시간대에 A의 쓰기를 보는 것처럼 나타난다 (쓰기 자체는 원자적이지만 쓰기로부터 발생된 메시지들이 해당 메시지들의 도착 여부와는 상관없이 진행되는 경우가 존재해 sequential consistency를 망치고 있는 것이다. P3는 P2에서 업데이트하는 B의 값에만 의존적이고 동시에 네트워크 상황에 영향을 받을 수 있도록 설계되었기 때문에 일어난 일이다). 무효화를 기반으로 하는 scheme에서 유사한 상황이 일어날 수 있다.
Sequential consistency의 위와 같은 위반은 P2가 A에 write 함으로써 발생하는 업데이트를 P3가 확인하기 전에 P2가 A에 쓴 값을 반환하는 것이 허용되기 때문에 일어난다. 이러한 위반을 방지하기 위한 하나의 가능한 제한으로는 해당 값을 읽는 것을 모든 캐시된 복사본들이 해당 쓰기로부터 생성된 무효화 또는 업데이트 메시지의 수령을 확인할 때까지 새롭게 쓰인 값의 반환하는 것을 금지하는 것이다. 이 조건은 무효화 기반 프로토콜을 보장하므로 간단하다. 업데이트 기반 프로토콜은 더욱 어려운데 왜냐하면 무효화와는 달리, 업데이트는 직접 새로운 값을 다른 프로세서들에게 제공하기 때문이다. 하나의 해결책으로는 투 페이즈 업데이트 스킴(two phase update scheme)을 사용하는 것이다. 첫 번째 페이즈는 업데이트를 프로세서 캐시에게 보내는 과정과 이러한 업데이트를 위한 acknowledgement를 받는 과정을 포함한다. 이 페이즈에서는 업데이트된 위치의 값을 읽을 수 있는 프로세서는 존재하지 않는다. 두 번째 페이즈는 확인 메시지(confirmation message)가 모든 acknowledgements의 수령을 확인하기 위해 업데이트된 프로세서 캐시에게 보내진다. 프로세서는 일단 두 번째 페이즈에서 확인 메시지(confirmation message)를 받았을 때에 업데이트된 값을 사용할 수 있다. 하지만, 쓰기를 수행한 프로세서는 첫 번째 페이즈를 끝으로 쓰기를 마치는 것으로 간주할 수 있다.
5.2.3에서는 쓰기의 원자성에 대한 환상을 유지하기 위한 방법을 제시한다. 먼저, 예시를 통해 가능한 멀티 프로세서 상황을 가정하고 sequential consistency이 위반될 수 있는 상황을 보여준다. 보통 일반적인 상호 연결 네트워크 상황에서 발생 가능하며, 각 메모리 오퍼레이션은 원자적이지만 결과물은 원자적이지 않은 것처럼 보이면서 환상을 제공할 수 없는 상황이 되어 버린다.
그래서 이를 해결하기 위해 제시한 하나의 해결책으로써 투 페이즈 업데이트 스킴을 들었다. 1. 업데이트했다는 것을 다른 프로세서들에게 알리는 과정(이 기간에 쓰기를 실행한 프로세서를 제외한 나머지들은 업데이트된 해당 값의 읽기 행위가 금지된다), 2. 프로세서 캐시가 페이즈 1에서 보낸 확인 메시지를 받고 확인하는 과정(확인이 된 경우에만 해당 프로세서 내에 존재하는 캐시 안에 존재하는 업데이트된 값의 사용이 허용된다).
5.3 Compilers
컴파일러와 함께하는 sequential consistency 관점에서 프로그램 순서와의 상호작용은 하드웨어와의 상호작용과 유사하다. 특히, 지금까지 논의했던 모든 프로그램 조각들을 통해서 컴파일러로부터 생성된 공유 메모리 오퍼레이션의 재정렬은 하드웨어를 통해 생성된 재정렬과 유사한 형태로 sequential consistency의 위반으로 이어진다. 그러므로, 더 정교한 분석이 없는 상황에서는 공유 메모리 오퍼레이션들 사이의 프로그램 순서를 지키는 것이 컴파일러의 중요 요구 사항이다. 이 요구 사항은 메모리 재정렬을 일으킬 수 있는 단일 프로세서 컴파일러 최적화를 직접 제한한다. 여기에는 code motion, register allocation, common sub-expression elimination과 같은 간단한 (컴파일러) 최적화들과 loop blocking 또는 software piplining과 같은 더 정교한 최적화들을 포함한다.

재정렬 효과에 더해 register allocation과 같은 최적화들 또한 차례로 sequential consistency를 위반할 수 있는 특정 공유 메모리 오퍼레이션의 제거를 초래한다. Figure 5(b)의 코드를 고려해보자. 만약 컴파일러 레지스터가 (레지스터 안에 Head의 한 번 읽은 다음 레지스터 내에 있는 값을 읽음으로써) Head 위치를 P2에 할당하면, (P2에서의 그 한 번 읽기가 Head의 오래된 값을 반환한다면) P2의 반복문은 몇몇 실행에선 절대 종료하지 않을지도 모른다. 하지만, 해당 반복문은 모든 순차적인 일관된 실행 코드 실행 안에서는 종료가 보장된다. 문제의 원인은 P2의 레지스터에 Head를 할당하는 것이 P2가 P1이 쓴 새로운 값을 관찰하지 못하게 하기 때문이다.
요약하자면, 공유 메모리 병렬 프로그램을 위한 컴파일러는 sequential consistency가 유지되기 위해서라면 단일 프로세서 안에서 사용되는 많은 일반적인 최적화를 직접 적용할 수 없다. 위의 논평들은 명시적으로 병렬 프로그램을 위한 컴파일러에 적용한다; 순차 코드를 병렬화하는 컴파일러들은 본질적으로 최적화가 안전하게 적용될 수 있는 시기를 결정하기 위해 그들이 만들어낸 병렬 프로그램의 결과물에 대한 충분한 정보를 가지고 있다.
5.4 Summary for Sequential Consistency
위의 논의에서 sequential consistency는 많은 하드웨어와 컴파일러 최적화를 제한한다는 것은 명백하다. Sequential consisteny의 단순한 하드웨어 구현은 일반적으로 다음의 두 가지 요구 사항을 만족시킬 필요가 있다. 하나는, 프로세서가 반드시 이전 메모리 오퍼레이션이 프로그램 순서에 따른 다음 메모리 오퍼레이션으로 진행하기 전에 끝나는 것을 보장하는 것이다. 우리는 이 요구 사항을 프로그램 순서(program order) 요구 사항이라고 부른다. 일반적으로 쓰기 완료를 결정하는 것은 메모리로부터의 명시적인 acknowledgement message를 요구한다. 추가적으로, 캐시 기반 시스템에서는 쓰기는 반드시 모든 캐시된 복사본을 위한 무효화 또는 업데이트 메시지를 생성해야 하고, 쓰기는 타깃 캐시가 생성된 무효화 또는 업데이트를 확인했을 때만 완료된 것으로 간주된다. 두 번째 요구 사항은 오직 캐시 기반 시스템에 속하고 쓰기 원자성(write atomicity)을 고려해야 한다. 이는 같은 위치에서의 쓰기가 직렬화되고(예시 - 동일한 위치에 대한 쓰기는 모든 프로세서에 동일한 순서로 표시된다), 쓰기에 의해 생성된 모든 무효화 또는 업데이트가 확인될 때까지 쓰기 값이 읽기에 의해 반환되지 않아야 한다(예시 - 쓰기가 모든 프로세서에게 보일 때까지). 우리는 이를 쓰기 원자성(write atomicity)라고 부른다. 컴파일러의 경우, 프로그램 순서 요구 사항의 유사점이 간단한 구현에 적용된다. 게다가, 레지스터 할당과 같은 최적화를 통해 메모리 오퍼레이션 제거 또한 sequential consistency를 위반할 수 있다.
수많은 테크닉들이 sequential consistency를 위반하지 않으면서 하드웨어와 컴파일러에 의한 특정 최적화의 사용을 가능하게 하기 위해 제안되어 왔다; 대체로 성능을 향상할 가능성을 가지는 것들이 아래에서 논의된다.
우리는 먼저 캐시 일관성(cache coherence)을 위한 하드웨어 서포트를 가지는 순차 일관 시스템에 두 가지 적용 가능한 하드웨어 테크닉을 논의할 것이다 [10]. 첫 번째 테크닉은 프로그램 순서 요구 사항(예시 - write buffer에 있는 모든 연기된 쓰기를 위한 프리페치 배타적 요청들을 발행함)으로 인해 미뤄진 모든 쓰기 오퍼레이션의 소유권을 자동으로 프리페치하기 때문에, 지연된 쓰기 서비스가 프로그램 순서 안에서 진행하는 오퍼레이션들과 부분적으로 겹친다. 이 테크닉은 무효화 기반 프로토콜을 사용하는 캐시 기반 시스템에서만 적용 가능하다. 두 번째 테크닉은 프로그램 순서 요구 사항 때문에 연기된 읽기 작업을 투기적으로 서비스한다; 읽기가 더 간단한 구현에서 실행되기 전에 읽기 라인이 무효화되거나 업데이트되는 상황과 같이 자주 발생하지 않는 경우에서의 읽기와 후속 오퍼레이션들을 단순히 롤백(rolling back)하고 재실행함으로써 sequential consistency가 보장된다. 후자의 테크닉은 대부분의 롤백 시스템에서 이미 branch mispredictions를 다루기 위해 존재하기 때문에 동적으로 스케줄 된 프로세서에게 적합하다. 위의 두 테크닉은 몇몇 차세대 마이크로프로세서들(예시-MIPS R1000, Intel P6)에 의해 지원될 것이며, 이와 같이 더 효율적인 sequential consistency 하드웨어 구현을 가능케 한다.
다른 레이턴시 하이딩 테크닉들(latency hiding techniques)은, non-binding software prefetching 또는 다중 컨택스트를 위한 하드웨어 지원과 같이, 순차 일관 하드웨어의 성능을 향상한다는 것을 보여주었다. 그러나, 위의 테크닉들은 relaxed memory consistency와 결합해서 사용할 때에도 유익하다.
마지막으로, Shasha와 Snir은 sequential consistency를 위반하는 일 없이 메모리 오퍼레이션이 재정렬될 수 있는 시기를 탐지하는 컴파일러 알고리즘을 개발했다 [18]. 이러한 분석은 컴파일러에 의해 재정렬이 안전하다고 분석된 오퍼레이션 페어만을 재정렬함으로써 하드웨어 및 컴파일러 최적화를 구현하기 위해 사용할 수 있다. Shasha와 Snir의 알고리즘은 지수 복잡도를 가진다 [15]; 더 최근에는, SPMD 프로그램을 위한 다항식 복잡도를 가지는 새 알고리즘이 제안됐다 [15]. 하지만, 두 알고리즘 모두 다른 프로세서의 두 오퍼레이션이 충돌하는지 아닌지 판단하기 위해(alias analysis와 비슷함) 전역 의존성 분석(global dependence analysis)이 필요하다; 이 분석은 어렵고 알고리즘의 효율성을 낮출 수 있는 보수적인 정보를 종종 도출한다.
위의 하드웨어 및 컴파일러 테크닉이 보다 완화된 일관성 모델의 성능에 접근할 수 있을지는 아직 미지수다. 이 글의 나머지 부분은 sequential consistency에 제한됐던 많은 최적화를 가능케 하는 메모리 일관성 모델의 완화에 집중한다.
6. Relaxed Memory Models
Sequential consistency의 대체제로서 몇몇 relaxed memory consistency model은 학술적이고 상업적인 환경 안에서 제안되었다. 이러한 모델의 대부분의 원래 설명은 매우 다양한 사양 방법론과 형식주의 수준에 기초하고 있다. 이번 섹션의 목표는 이런 모델들을 간단하고 통일된 용어를 사용해서 묘사할 것이다. 이러한 모델들의 원래 사양은 모델에 의해 가능한 시스템 최적화를 강조한다; 이번 섹션의 설명에서는 시스템 중심의 강조점을 유지한다(retain). 하드웨어 공유 메모리 시스템을 위해 제안된 모델에 집중한다; 소프트웨어로 지원하는 공유 메모리 시스템을 위해 제안된 relaxed model은 설명하기 더 복잡하고 이 논문의 범위를 벗어난다. 프레임워크 내 몇몇 모델의 공식 설명과 함께, 하드웨어 및 소프트웨어 기반 모델을 설명하기 위한 보다 공적이고 단일화된 시스템 중심의 프레임워크는 이전에 다뤘다 [8, 6].
다양한 모델을 특징짓기 위해 사용하는 단순한 방법론을 설명함으로써 이번 섹션을 시작하고, 이후 이 방법론을 사용해 각 모델을 설명한다.
6.1 Characterizing Different Memory Consistency Models
두 가지 핵심 특징에 기초한 relaxed memory consistency model을 분류한다: (1) 어떻게 프로그램 순서 요구 사항을 완화하는지, (2) 어떻게 쓰기 원자성 요구 사항을 완화하는지.
프로그램 순서 완화의 관점에서는, 접근한 위치의 모든 캐시 복사본들이 쓰기로부터 생성된 무효화 또는 업데이트 메시지를 받기 전에, 읽기가 또 다른 프로세서의 쓰기 값을 반환할 수 있는지 없는지에 따라 모델들을 구분한다; 구체적으로는, 모든 다른 프로세서가 해당 쓰기를 보기 전에. 이 완화는 5.2 섹션에서 설명했었고 캐시 기반 시스템에만 적용된다.
마지막으로, 프로그램 순서와 쓰기 원자성에 관련된 완화를 고려하는데, 여기서 프로세서는 다른 프로세서에게 쓰기가 보이기 전에 자신의 이전 쓰기의 값을 읽는 것이 가능하다. 캐시 기반 시스템에서는 쓰기가 같은 위치로의 다른 쓰기에 대하여 직렬화되기 전에, 그리고 쓰기에 대한 무효화/업데이트가 모든 다른 프로세서에게 도착하기 전에, 이 완화는 읽기가 쓰기 값을 반환할 수 있다 (요약하자면, 캐시 기반 시스템 기준에서 완화는 말 그대로 이전 sequential consistency에서 지켜졌던 엄격한 조건을 완화하는 방향의 최적화다. 그래서 어떤 읽는 시점에서 아직 다른 쓰기로부터 발생한 무효화/업데이트 메시지가 현재 프로세서에는 도착하지 않았지만 읽기를 수행하는 그 시점에서 sequential consistency와는 달리 자신의 캐시에 저장된 값의 읽기를 허용한다는 의미다). 이러한 완화를 허용하는 일반적인 최적화의 한 예시로는 write buffer 안의 쓰기 값을 같은 프로세서의 이후 읽기로 전달하는 것이다. 캐시 기반 시스템에서 또 다른 일반적인 예시는 프로세서가 write-through 캐시에 쓰고, 쓰기가 완료되기 전에 캐시로부터 값을 읽는 경우다. 우리는 이 완화를 따로따로 고려하는데, 왜냐하면 몇몇 모델이 그들의 원래 정의 안에서 이 최적화를 명확하게 명시하지 않더라도, 모델의 시멘틱을 위반하지 않은 채로 많은 모델에 안전하게 적용할 수 있기 때문이다. 예를 들어, 이 완화는 모든 다른 프로그램 순서와 원자성 요구 사항이 유지되는 한 [8] sequential consistency에 의해 허용되므로, 이전 섹션에서 설명하지 않았다. 게다가, 이 완화는 이번 섹션에서 설명될 모델들 중 하나를 제외한 나머지 모두에 안전하게 적용할 수 있다.

Figure 7은 위에서 논의한 완화를 요약한다. Relaxed model은 또한 일반적으로 (Figure 7에서의) 완화를 오버라이드 하는 메커니즘을 프로그래머에게 제공한다. 예를 들어, 명시적 fence 명령어는 프로그램 순서 완화를 오버라이드 하기 위해 제공될 수도 있다. 우리는 일반적으로 그러한 메커니즘을 모델을 위한 안전망(safety net)이라고 부르고, 각 모델마다 제공된 안전망의 유형에 대해 설명할 것이다. 각 모델은 특정 순서 제약들을 강화하는 보다 미묘한 방법을 제공할 수도 있다; 요약하자면, 우리는 보다 단순한 안전망에 대해서만 설명할 것이다.

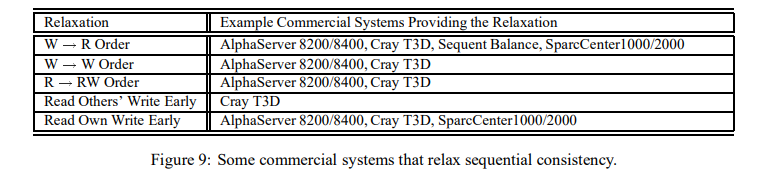
Figure 8은 이 섹션의 남은 부분을 설명하는 모델들의 개요를 제공한다. 이 figure는 단순한 모델의 구현이 프로그램 순서 또는 위에서 설명한 쓰기 원자성 완화를 효율적으로 이용할 수 있는지 아닌지에 대해 보여주고, 각 모델로부터 제공되는 안전망을 언급한다. 이 figure는 언제 프로그래머가 위의 완화들을 발견할 수 있는지 또한 알려준다; i.e., 프로그래머가 프로그램 결과에 영향을 줄 수 있을 때. Figure 9는 위의 완화를 허용하는 상업 시스템의 예시를 보여준다. 간단히 하자면, 우리는 명령어 패치 또는 다중 세분화(granularity) 오퍼레이션(e.g., byte, word 오퍼레이션)과 같은 문제와 관련된 모델의 시멘틱을 설명하려 하지 않는다; 몇몇 이러한 모델에서 정의되는 그런 시멘틱일지라도.
이어지는 섹션은 각 모델을 자세히 설명하고 각 모델에서의 하드웨어 및 컴파일러 구현이 미치는 영향을 설명한다. 이번 설명을 통해 다음의 제약들이 만족된다는 암묵적인 가정을 한다. (제약 1) 먼저, 모든 모델이 최종적으로 모든 프로세서에게 보이고, 같은 위치에서의 쓰기가 직렬화되기 위해 쓰기가 필요하다. 이 요구 사항들은 공유된 데이터가 캐시되어 있지 않는다면 평범하게 충족되고, 공유된 데이터 캐싱의 존재 안에서 하드웨어 캐시 일관성 프로토콜을 통해 보통 충족된다. (제약 2) 두 번째, 모든 모델이 단일 프로세서 데이터를 강화하고 의존성을 제어한다고 가정한다. (제약 3) 마지막으로, 읽기부터 이후의 쓰기 오퍼레이션까지 프로그램 순서를 완화하는 모델은 멀티 프로세서 데이터의 미묘한 형태를 유지해야만 하고 의존성을 제어해야만 한다 [8, 1]; 후자의 제약은 본질적으로 우리가 알고 있는 모든 프로세서 설계에 의해 유지되며 또한 컴파일러에 의해 쉽게 유지될 수 있다.
6.2 Relaxing the Write to Read Program Order
첫 번째로 설명할 모델의 집합은 다른 위치로의 읽기 이후에 오는 쓰기의 경우에서 프로그램 순서 제약을 완화한다. 이 모델들은 IBM 370 model, SPARC V8 total store ordering model(TSO), processor consistency model (PC) (Goodman이 정의한 processor conistency model과 다르다)를 포함한다.
이 모델이 가능케 하는 핵심 프로그램 순서 최적화는 같은 프로세서에서 이전 쓰기의 관점에서 읽기가 재정렬되도록 할 수 있다. 이러한 재정렬의 결과로써, Figure 5(a)에서 예시와 같은 프로그램들은 순차 일관 결과를 제공하는 것이 실패할 수 있다. 하지만, Figure 5(b)와 Figure 5(c)에서 설명한 sequential consistency의 위반은 나머지 프로그램 순서 제약의 강제 때문에 일어날 수 없다.
세 가지 모델은 언제 읽기가 쓰기 값을 반환할 수 있는지에 따라 차이가 있다. IBM 370 model은 가장 엄격한데 왜냐하면 모든 프로세서에서 쓰기가 보이기 전에는 쓰기 값을 반환하는 것을 읽는 것이 금지되기 때문이다. 그러므로, 프로세서가 이전에 보류한 쓰기 주소와 동일한 주소로의 읽기를 실행한 경우일지라도, 읽기는 모든 프로세서로부터 쓰기가 보일 때까지 미뤄져야만 한다. TSO model은 같은 장소에서의 다른 쓰기 관점에서 쓰기가 직렬화되기 전일지라도 읽기가 자신의 프로세서의 쓰기 값을 반환할 수 있도록 함으로써 위의 요구 사항을 부분적으로 완화한다. 하지만, sequential consistency 관점에서 보면, 다른 모든 프로세서에게 보일 때까지 읽기는 다른 프로세서의 쓰기 값을 반환할 수 없다. 마지막으로, PC model은 쓰기가 직렬화되거나 다른 프로세서에게 보이기 전에 읽기는 모든 쓰기 값을 반환할 수 있다는 것과 같은 제약 조건들을 완화한다. Figure 10은 위의 세 가지 모델 사이의 이러한 차이점들을 보여주는 예시 프로그램을 나타낸다.

다음으로 위의 세 모델의 안전망 특징을 고려한다. 쓰기부터 이후의 읽기까지의 프로그램 순서 제약을 강화하기 위해, IBM 370 model은 두 오퍼레이션 사이에 위치할 수도 있는 특별한 serialization instructions를 제공한다. 몇몇 직렬화 명령어는 동기화(e.g., compare&swap)를 위해 사용되는 특별한 메모리 명령어인데, 반면에 다른 명령어들은 branch와 같은 비 메모리(non-memory) 명령어다. Figure 5(a)에서의 예시 프로그램을 다시 언급하자면, 각 프로세서에서의 쓰기 후에 직렬화 명령어를 위치시키는 것은 IBM 370 model에서 실행될 때조차도 프로그램의 순차 일관된 결과를 제공한다.
그러니까 sequential consistency를 위반할 수 있는 write buffer system에서도 IBM 370 model의 직렬화 명령어를 통해 sequential consistency를 지킬 수 있다는 것이다.
이러한 직렬화 명령어는 IBM 370 model에 의해 제공되는 명시적인 안전망이라고 할 수 있다.

IBM 370과는 달리, TSO와 PC model은 명시적인 안전망을 제공하지 않는다. 그럼에도 불구하고, 프로그래머는 쓰기 및 이후의 읽기 사이에 프로그램 순서가 유지된다는 환상을 제공하는 읽기-수정-쓰기(read-modify-write) 오퍼레이션을 사용할 수 있다. TSO에서는, 쓰기 또는 읽기 중 하나가 이미 읽기-수정-쓰기의 부분이거나 읽기-수정-쓰기로 대체된 경우 프로그램 순서가 유지된다. 읽기를 읽기-수정-쓰기로 대체하기 위해, 읽기-수정-쓰기 안의 쓰기는 읽은 값을 다시 쓰는 "더미(dummy)" 쓰기여야 한다. 비슷하게, 읽기-수정-쓰기 안의 쓰기를 대체하는 것은 읽기가 반환하는 것과는 상관없이 원하는 값을 다시 쓰는 것이 필요하다. 그러므로, 위의 테크닉은 읽기-수정-쓰기 명령어를 위한 그런 유연성을 제공하는 설계에만 적용할 수 있다. PC에서는, 읽기가 읽기-수정-쓰기로 대체되거나 이미 일부분일 경우 쓰기와 이후의 읽기 사이의 프로그램 순서가 유지된다. TSO와 달리, 쓰기를 읽기-수정-쓰기로 대체하는 것은 PC 안의 순서를 강제하는 것은 충분하지 않다. TSO는 읽기-수정-쓰기 행위에 보다 엄격한 제약을 두지만, PC는 같은 위치에서의 쓰기만 필요로 하기 때문에 차이가 발생한다.
다음으로 쓰기의 원자성 요구 사항을 강화하는 안전망에 대해 고려해보자. IBM 370은 원자성을 완화하지 않기 때문에 안전망이 필요 없다. TSO에서는, 쓰기 원자성을 위한 안전망이 같은 프로세서의 동일한 위치로의 읽기 이후에 오는 쓰기에 대해서만 필요하다; 원자성은 위에서 설명한 대로 읽기-수정-쓰기를 사용해서 쓰기부터 읽기까지의 프로그램 순서를 보장함으로써 보존할 수 있다. PC에서는, 쓰기 값을 반환할 수도 있는 모든 읽기가 읽기-수정-쓰기의 일부분이거나 대체되었을 경우 쓰기가 원자적이라는 것을 보장한다 (그러니까 PC에서는 위에서도 언급된 것처럼 "쓰기"에 대해서만, 그것도 읽기-수정-쓰기와 관련되었을 때에만 그 원자성이 보장된다).
위 모델에서 읽기-수정-쓰기 오퍼레이션이 요구되는 프로그램 순서 또는 원자성을 보장하는 방법의 추론은 이 논문의 범위를 벗어난다 [7]. TSO, PC와 같은 모델에서 읽기-수정-쓰기를 안전망으로 의지하는 것은 몇 가지 불이익을 가진다. (불이익 1) 먼저, 시스템이 모든 읽기 또는 쓰기를 적절히 대체하기 위해 사용되는 일반적인 읽기-수정-쓰기를 구현하지 못할 수도 있다. (불이익 2) 두 번째로, 읽기를 읽기-수정-쓰기로 대체하는 것은 쓰기의 수행에 있어 추가적인 비용을 유발한다 (e.g., 어떤 라인의 다른 복사본들을 무효화시키기). 물론, 특정 읽기 또는 쓰기 오퍼레이션이 이미 읽기-수정-쓰기 오퍼레이션의 일부분인 경우, 안전망은 오버헤드를 발생시키지 않는다. 게다가, 대부분의 프로그램이 정확성을 위해 프로그램 순서를 읽거나 원자성을 쓰는 것에 빈번히 의존하지 않는다. (무슨 소리야 이게)
쓰기 후 읽기의 프로그램 순서를 완화하는 것은 쓰기 오퍼레이션의 지연 시간을 효율적으로 숨김으로써 하드웨어 수준에서 상당히 성능을 개선시킬 수 있다 [9]. 하지만, 컴파일러 최적화에서는, 이러한 완화 자체로는 실전에서 유용하지 않다. 그 이유는 읽기 및 쓰기는 보통 프로그램 안에서 정교하게 짜깁기(interleaved)될 수 있기 때문이다; 그러므로, 대부분의 컴파일러 최적화는 프로그램 순서에 따른 모든 두 개의 오퍼레이션의 재정렬에 대해 완벽한 유연성을 필요로 한다; 읽기 이후의 쓰기에 대해서만 재정렬하는 기능은 충분히 유연하지 않다.
6.3 Relaxing the Write to Read and Write to Write Program Orders
두 번째 모델의 집합 또한 다른 위치에서의 쓰기 간의 정렬 제약 조건을 없애므로써 프로그램 순서 요구 사항을 완화한다. SPARC V8 부분 저장 순서(partial store ordering) 모델(PSO)은 여기서 우리가 설명하는 유일한 예시다. 이전 모델의 집합에 비해 PSO에 의해 가능해진 추가적인 핵심 하드웨어 최적화는 같은 프로세서의 다른 위치로의 쓰기가 파이프라인 되거나 오버래핑되고 프로그램 순서를 벗어나 메모리나 다른 캐시된 복사본에 도달할 수 있는 것이다. 원자성 요구 사항과 관련해서, PSO는 프로세서가 자신의 쓰기 값을 먼저 읽도록 허용하고 다른 모든 프로세서에게 쓰기가 보이기 전에 또 다른 프로세서의 쓰기 값을 읽는 것을 금지함으로써 TSO와 동일하다. Figure 5(a), (b)의 프로그램을 다시 언급하자면, PSO는 비 순차적인 일관된 결과(non-sequentially consistent results)를 허용한다.
쓰기부터 읽기까지 프로그램 순서를 부여하고 쓰기 원자성을 강화하기 위해 PSO로부터 제공되는 안전망은 TSO와 동일하다. PSO는 두 쓰기 사이에 프로그램 순서를 부여하기 위해 명시적인 STBAR(store barrior; 메모리 베리어의 일종) 명령어를 제공한다. FIFO write buffer를 사용하는 구현을 통해 STBAR를 지원하는 한 가지 방법은 write buffer 안에 STBAR를 삽입하는 것과, STBAR 이후에 버퍼링된 쓰기 작업을 STBAR 이전에 버퍼링 되어 완료되기 전까지 지연시킵니다. 카운터(counter)는 STBAR가 완료되기 전에 모든 쓰기가 완료되었는지 확인하는 데 사용할 수 있다 - 메모리 시스템으로 전송되는 쓰기는 카운터를 증가시키고, 쓰기 확인은 카운터를 감소시키고, 카운터 0은 이전의 모든 쓰기가 종료되었음을 나타낸다. Figure 5(b)의 프로그램을 다시 언급하자면, 두 개의 쓰기 사이에 STBAR를 삽입하는 것은 PSO에서 순차적으로 일관된 결과를 보장한다.
이전 모델들의 집합의 관점에서, PSO에서 허용되는 최적화는 컴파일러에게 유용하기에 충분히 유연하지 않다.
6.4 Relaxing All Program Orders
설명할 마지막 모델들의 집합은 다른 위치에서의 모든 오퍼레이션 사이에서 프로그램 순서를 완화한다. 따라서, 읽기 또는 쓰기 오퍼레이션은 다른 위치에 대한 다음 읽기 또는 쓰기와 관련해서 겹쳐지거나 재정렬될 수도 있다. 우리는 약한 순서(weak ordering; WO) 모델, 두 가지 유형의 release(아마 =relaxed?) consisteny model (RCsc/RCpc), 그리고 상업용 아키텍처를 위해 제안된 세 가지 모델: Digital Alpha, SPARC V9 relaxed memory order (RMO), IBM PowerPC model에 대해 설명한다. Alpha를 제외한 위의 모델들은 같은 위치에 대한 두 개의 읽기의 재정렬도 가능하다. Figure 5를 다시 언급하자면, 위의 모델들은 figure 5에 나오는 모든 코드 예시에서 sequential consistency를 위반한다.
이전 모델들에 비해 허용된 추가적인 핵심 프로그램 순서 최적화는 읽기 오퍼레이션 이후의 메모리 오퍼레이션이 읽기 연산에 대해 겹치거나 재정렬될 수 있다는 것이다. 하드웨어 측면에서, 이러한 유연성은 논블로킹(lockup-free) 캐시 및 추측 기반 실행과 같은 기술이 지원되면서, 정적 (in-order) 혹은 동적 (out-of-order) 스케줄링 프로세서 중 하나의 컨텍스트 안에서 완전한 논블로킹 읽기를 구현함으로써 읽기 작업의 지연 시간을 숨길 가능성을 제공한다 [11].
이 집합의 모든 모델은 프로세서가 자신의 쓰기를 먼저 읽는 것을 허용한다. 그러나, RCpc 및 PowerPC는 단순한 구현이 읽기가 또다른 프로세서의 쓰기를 먼저 반환하는 것을 허용하는 유일한 모델들이다. WO, RCsc, Alpha, RMO의 보다 복잡한 구현은 위 조건을 달성할 수 있다. 하지만, 프로그래머의 관점에서 보면, WO, Alpha, RMO의 모든 구현은 쓰기 원자성의 환상을 반드시 유지해야 한다.1 RCsc는 이러한 관점에서 봤을 때 독특한 모델이다; 프로그래머는 RCsc의 복잡한 구현이 프로그램 결과에 영향을 줄 수 있는 방법으로 원자성을 잠재적으로 위반할 수 있기 때문에 원자성에 의존할 수 없다.
위의 모델들은 제공되는 안전망의 유형에 따라 두 가지 카테고리로 분류될 수도 있다. WO, RCsc, RCpc 모델은 메모리 연산의 타입에 따라 구별하고, 몇몇 연산 유형을 위한 보다 엄격한 순서 제약 사항을 제공한다. 반면에, Alpha, RMO, PowerPC 모델은 다양한 메모리 연산 간에 프로그램 순서를 부여하기 위해 명시적인 울타리 명령어(fence instructions)를 제공한다. 이후에는 이러한 각 모델을 그들의 안전망에 초점을 맞춰서 더욱 더 자세히 묘사한다. 이번 그룹의 모델들을 위한 컴파일러 구현에 대한 함축적 의미는 이 섹션의 끝에서 설명한다.
6.4.1 Weak Ordering (WO)
약한 순서 모델은 메모리 오퍼레이션을 두 가지 카테고리로 분류한다: 데이터 오퍼레이션 및 동기화 오퍼레이션. 두 오퍼레이션 간의 프로그램 순서를 강화하기 위해 프로그래머는 오퍼레이션들 중 최소 하나는 동기화 오퍼레이션인지 확인할 필요가 있다. 이 모델은 동기화 오퍼레이션 간의 데이터 영역으로 메모리 오퍼레이션 순서 변경은 일반적으로 프로그램 정확성에 영향을 미치지 않는다는 직관에 기초한다.
동기화로 구별되는 오퍼레이션들은 프로그램 순서를 강화하기 위한 안전망을 효율적으로 제공한다. 우리는 하드웨어에서 적절한 기능을 지원하는 간단한 방법을 짧게 설명한다. 각 프로세서는 두드러진 오퍼레이션들을 추적하는 카운터를 제공할 수 있다. 이 카운터는 프로세서가 오퍼레이션을 실행할 때 증가하고, 이전에 실행된 오퍼레이션이 끝났을 때 감소한다. 각 프로세서는 동기화 오퍼레이션이 모든 이전 오퍼레이션들이 끝날 때까지 실행되지 않도록 보장해야하는데, 이는 카운터의 0 값에 의해 시그널 된다. 게다가, 이전 동기화 오퍼레이션이 끝날 때까지 실행되는 오퍼레이션은 없다. 즉, 두 동기화 오퍼레이션 간의 메모리 오퍼레이션은 서로에 의해 여전히 순서가 변경되고 오버래핑될 수도 있다.
약한 순서 모델은 쓰기가 항상 프로그래머에게는 원자적인 것처럼 보이도록 해야한다; 그러므로, 쓰기 원자성을 위한 안전망은 필요하지 않다.
약한 순서(WO; Weak Ordering) 모델은 프로그래머에게는 쓰기 원자성을 보장하는 것처럼 보이게 만든다. 하지만, 실제로는 최적화 등의 이유로 일어나는 재정렬 또는 오버래핑을 허용한다. 이는 메모리 오퍼레이션을 두 가지 측면으로 분류해서 동작시킴으로써 쓰기 원자성을 보장하도록 만든다. 두 가지 측면이란 데이터 오퍼레이션과 동기화 오퍼레이션을 말한다. 동기화 오퍼레이션은 이전 오퍼레이션들이 반드시 끝난 후에 실행되어야 하고, 동기화 오퍼레이션 간에는 여전히 순서가 바뀌거나 오버래핑될 수 있다.
6.4.2 Release Consistency (RCsc/RCpc)
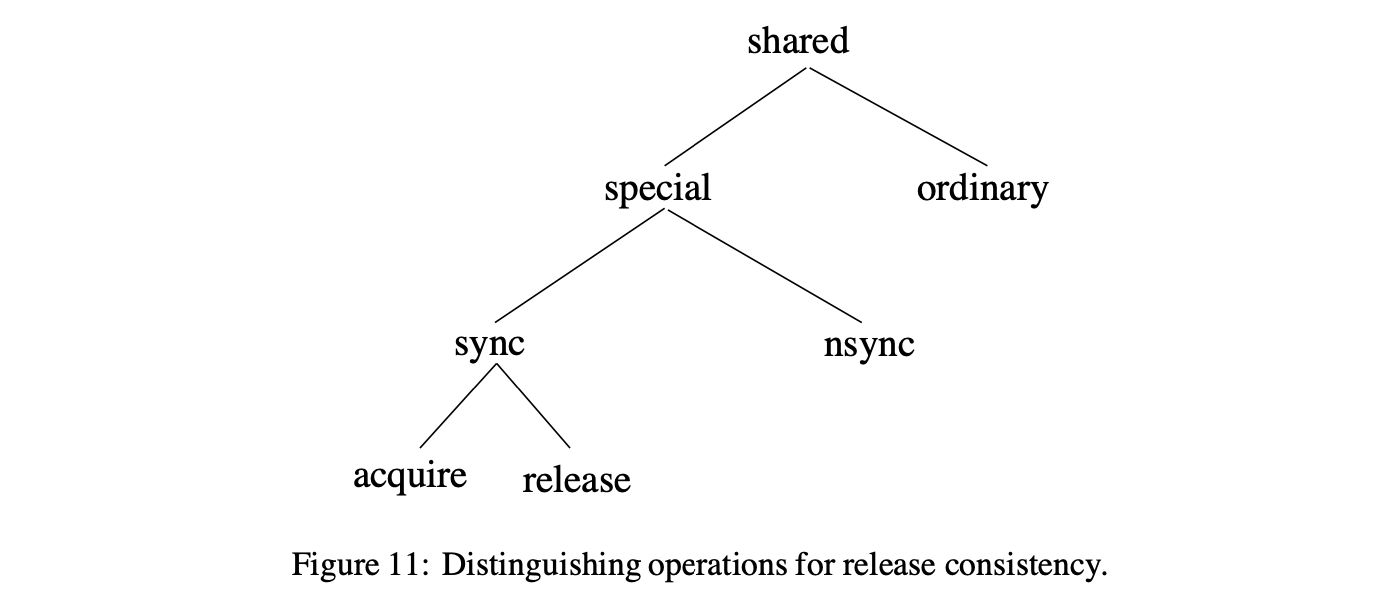
약한 순서 모델과 비교하자면, 일관성 완화(release consistency)는 메모리 오퍼레이션 사이의 거리 또한 제공한다. Figure 11은 이러한 메모리 오퍼레이션의 분류를 그림을 넣어 보여준다. 오퍼레이션은 먼저 평범함(ordinary) 또는 특별함(special)으로 구분된다. 이 두 카테고리는 WO의 데이터 및 동기화와 약하게 일치한다. 특별한 오퍼레이션은 동기(sync) 또는 비동기(nsync) 오퍼레이션으로 다시 구분된다. 동기(sync)는 직관적으로 동기화 오퍼레이션과 일치하는 반면에, 비동기(nsync)는 동기화에서 사용하지 않는 비동기 데이터 오퍼레이션 또는 특별한 오퍼레이션과 일치한다. 마지막으로, 동기 오퍼레이션은 습득(acquire) 또는 완화(release) 오퍼레이션으로 다시 구분된다. 직관적으로, acquire은 공유된 위치의 집합으로의 접근 권한 얻기를 수행하는 읽기 오퍼레이션이다 (e.g., lock 오퍼레이션 또는 flag를 세팅하기 위한 spinning). Release는 공유된 위치의 집합으로의 접근을 위한 권한을 승인받기 위해 수행되는 쓰기 오퍼레이션이다 (e.g., unlock 오퍼레이션 또는 flag 설정하기).
특별한 오퍼레이션 사이에서 유지하는 프로그램 순서에 기반해 달라지는 두 가지 유형의 release consistency가 있다. 첫 번째 유형(RCsc)은 특별한 오퍼레이션 사이의 sequential consistency를 유지하는데, 반면 두 번째 유형(RCpc)은 특별한 오퍼레이션 사이의 processor consistency를 유지한다. 아래에서 우리는 다른 위치에서의 오퍼레이션을 위한 두 모델의 프로그램 순서 제약 조건들을 설명한다. 우리의 표기법으로, A → B는 만약 유형 A 오퍼레이션이 프로그램 순서 안에서 유형 B 오퍼레이션에 선행할 때, 두 오퍼레이션 간의 프로그램 순서가 강화된다는 것을 암시한다.
RCsc에선, 다음의 제약 조건이 있다:
● acquire → all, all → release, and special → special.
RCpc에선, 특별한 오퍼레이션 간에 쓰기에서 읽기 프로그램 순서가 제거된다:
● acquire → all, all →release, and special → special / special write 이후의 special read는 제외.
그러므로, 한 쌍의 오퍼레이션 사이의 프로그램 순서를 강화하는 것은 위의 정보를 바탕으로 적절한 오퍼레이션을 구별하거나 라벨링함으로써 이뤄질 수 있다. RCpc에서는, 쓰기부터 읽기 오퍼레이션까지 프로그램 순서를 적용하려면 PC 모델과 유사한 읽기-수정-쓰기 오퍼레이션을 사용해야 한다. 거기다, 정렬된 쓰기가 평범(ordinary)하다면, 읽기-수정-쓰기 안에서의 쓰기는 완화가 필요하다; 반면에, 읽기-수정-쓰기 안의 쓰기는 모든 특별한(special) 쓰기가 될 수 있다. 비슷하게, RCpc에서 쓰기를 원자적인 것처럼 보이게 만들기 위해서는, 읽기-수정-쓰기 오퍼레이션이 PC 모델과 유사한 적절한 오퍼레이션과 대체될 수 있다. 일찍이 언급했듯이, 쓰기는 RCsc의 보다 복잡한 구현에서 비-원자적(non-atomic)인 것처럼 보일 수 있다. 쓰기의 원자성을 보존하려면 충분한 오퍼레이션을 special로 라벨링함으로써 성취될 수 있다; 하지만, 어떻게 이것이 이루어지는지 정확히 설명하는 것은 이 기사에서 제공하는 간단한 프레임워크에선 어렵다. 우리는 RCsc모델이 대규모 프로그램을 위한 저수준의 사양을 프로그래머가 직접 추론할 필요성을 덜어주는 고수준 추상화(섹션 7에서 설명됨) 또한 동반된다는 것을 알고 있어야 한다 [13].
6.4.3 Alpha, RMO, and PowerPC
Alpha, RMO, PowerPC 모델은 모두 그들의 안전망을 통해 명시적인 fence instructions를 제공한다.
Alpha 모델은 "memory barrier(MB)와 write memory barrier(WMB)"라는 두 가지 다른 fence instruction을 제공한다. MB 명령어는 MB 이전의 모든 메모리 오퍼레이션과 MB 이후의 모든 메모리 오퍼레이션의 프로그램 순서를 유지하기 위해 사용될 수 있다. WMB 명령어는 write 오퍼레이션들 사이에서만 이러한 보장을 제공한다. Alpha 모델은 쓰기 원자성을 위한 안전망을 필요로 하지 않는다.
SPARC V9 RMO 모델은 다양한 유형의 fence instruction을 제공한다. 효율적으로, MEMBAR 명령어는 미래의 읽기와 쓰기 오퍼레이션에 대해 이전 읽기와 쓰기 오퍼레이션의 조합을 지시하기 위해 맞춤화될 수 있다; 4-bit 인코딩은 read-to-read, read-to-write, write-to-read, write-to-write 순서의 모든 조합을 특정하는 데에 사용된다. MEMBAR은 이후의 읽기에 대해 쓰기를 정렬하는 데에 사용될 수 있다는 사실은 그 순서로 만들기 위해 읽기-수정-쓰기를 사용할 필요성을 덜어주는 반면에, SPARC V8 TSO 또는 PSO 모델은 필요로 한다. TSO 및 PSO와 비슷하게, RMO 모델은 쓰기 원자성을 위한 안전망을 필요로 하지 않는다.
PowerPC 모델은 SYNC 명령어라고 불리는 단일 fence instruction을 제공한다. 프로그램 순서를 적용하기 위해, SYNC 명령어는 한 가지 예외를 빼면 Alpha 모델의 MB 명령어와 유사한 동작을 한다. 그 예외란 SYNC가 같은 위치의 두 읽기 사이에 위치하더라도, 두 번째 읽기는 첫 번째 읽기보다 오래된 쓰기 값을 반환할 수 있다는 것이다; i.e., 읽기는 프로그램 순서에서 벗어나 있는 것처럼 보인다 (read->SYNC->read 순서로 메모리 오퍼레이션이 배치되어 있음에도 두 번째에 위치한 read는 첫 번째의 read보다 먼저 오래된 값을 반환할 수 있다는 것. 즉 SYNC를 통해 memory barrier가 제공되어야 하는데 그렇지 않은 행동을 하는 명령어라는 것이다). 이는 프로그램 내에서 미묘한 정확도 문제를 생성할 수 있고, 같은 위치의 두 읽기 간의 프로그램 순서를 강화하기 위해 (PC 및 RCpc가 사용하는 것과 비슷하게) 읽기-수정-쓰기 오퍼레이션을 사용을 요구할 수도 있다. PowerPC 또한 쓰기가 다른 프로세서의 읽기에서 일찍이 보이는 것을 허용한다는 점에서 원자성 측면의 Alpha, RMO와 다르다; 그러므로, PC 및 RCpc와 유사하게, 읽기-수정-쓰기 오퍼레이션을 쓰기가 원자적인 것처럼 보이게 만들기 위해 사용될 필요가 있을지도 모른다.
6.4.4 Compiler Optimizations
이전 섹션의 모델들과는 달리, 모든 프로그램 순서를 완화하는 모델들은 공유 메모리 오퍼레이션의 일반적인 컴파일러 최적화를 허용하는 충분한 유연성을 제공한다. WO, RCsc, RCpc와 같은 모델에서는, 컴파일러가 두 개의 연이은 동기화 또는 특별 오퍼레이션 사이의 메모리 오퍼레이션을 제정렬하기 위한 유연성을 지닌다. 비슷하게, Alpha, RMO, PowerPC 모델에서는, 컴파일러가 연이은 fence instruction 간의 오퍼레이션을 재 정렬하기 위한 완전한(full) 유연성을 지닌다. 대부분의 프로그램이 이러한 오퍼레이션 또는 명령어를 드물게 사용하기 때문에, 컴파일러는 단일 프로세서 프로그램을 위해 사용되는 가상의 모든 최적화가 안전하게 적용되는 거대한 코드 영역을 가진다.
7. An Alternate Abstraction for Relaxed Memory Models
이전 섹션에서 설명한 relaxed memory model이 제공하는 유연성은 상당한 성능 향상을 보여주는 넓은 범위의 성능 최적화를 가능케 한다 [9, 11, 6]. 하지만, 보다 높은 성능은 프로그래머를 위한 보다 높은 수준의 복잡성에 의해 수반된다. 게다가, 다른 시스템에서 지원되는 미묘한 방식으로 인해 달라지는 다양한 시멘틱을 다루기 위해서는 프로그래머가 필요하고, 이러한 시스템 사이의 프로그램 포팅 작업을 복잡하게 한다. 프로그래밍 복잡성은 일반적으로 relaxed memory model에서 제공되는 시스템 중심의 사양으로 인해 발생한다. 그러한 사양들은 프로그래머에게 한 모델에서 허용되는 재정렬 및 원자성 최적화를 직접적으로 노출시키고, 정확성에 대한 근거를 위한 그러한 최적화의 존재 안에서 프로그래머가 프로그램의 동작을 고려하도록 만든다. 이것은 프로그래머에게 보다 단순한 관점의 시스템을 제공하기 위한 보다 높은 수준의 추상화를 고안한 인센티브를 제공하지만, 시스템 설계자들이 같은 유형의 최적화를 이용할 수 있다.
설명해 온 relaxed model을 위해, 프로그래머는 메모리 오퍼레이션의 적절한 순서와 원자성 요구사항을 부여하기 위해 충분한 안전망(e.g., fence instructions, 보다 보수적인 오퍼레이션 유형들, 또는 읽기-수정-쓰기 오퍼레이션)을 사용함으로써 프로그램의 정확성을 보장할 수 있다. 어려운 문제는 정확성을 위한 필수적인 순서 제약조건들을 식별하는 것이다. 예를 들어, 약한 순서(weak ordering; WO)와 같은 모델을 실행하는 Figure 1 안에서의 프로그램을 고려해보자. 이 예시에서는 정확성을 위한 다음의 순서들을 유지하기만 하면 충분하다: (1) P1에서, Head로의 쓰기와 Head에 쓰기 전의 오퍼레이션 사이의 프로그램 순서를 유지하기, (2) 다른 프로세서들에서, Head 읽기부터 이후의 오퍼레이션까지의 프로그램 순서를 유지하기. Head 읽기 및 쓰기는 실제로 동기화 오퍼레이션처럼 동작하고, 그렇게 식별함으로써 적절한 프로그램 순서가 WO과 같은 모델에 의해 자동으로 유지될 것이다. 이런 이슈를 인식하면서, WO와 같은 많은 모델들은 프로그래머가 "정확한" 동작을 보장하기 위해 해야만 하는 일에 대한 비공식적 조건들이 수반된다. 예를 들어, 약한 순서(weak ordering)는 프로그래머가 동기화 오퍼레이션을 식별하는 것이 필요하다. 하지만, 이러한 조건들의 비공식적 특성은 조건들이 넓은 범위의 프로그램을 넘어서 적용될 때 그 조건들을 애매모호하게 만든다 (e.g., 어떤 오퍼레이션이 정말로 동기화로 식별되어야 하는지). 그러므로, 많은 경우에서 프로그래머는 충분한 순서가 강제되는지 아닌지 결정하기 위해 낮은 레벨의 재정렬 최적화를 사용한 추론에 여전히 의지해야만 한다.
시스템 중심 사양에서처럼 성능 향상 최적화를 프로그래머에게 직접 노출시키기 보다는, 프로그래머 중심적 사양은 프로그래머가 프로그램에 대한 특정 정보를 제공해야 한다. 그러고 나서 이 정보는 프로그램의 정확성을 해치지 않은 채로 특정 최적화가 적용될 수 있는지 아닌지를 결정하는 시스템에 사용될 수 있다. 공식적인 프로그래머 중심 사양을 제공하기 위해서 우리는 먼저 프로그램의 "정확성"에 대한 개념을 정의할 필요가 있다. 이를 위한 명백한 선택은 sequential consistency인데, 그 이유는 정확성의 단일 프로세서 개념의 자연스러운 확장, 그리고 멀티 프로세서에서의 일반적으로 가장 많이 추측되는 정확성의 개념이기 때문이다. 두 번째는 프로그래머가 필요로 하는 정보는 반드시 정확하게 정의되어야 한다.
요약하자면, 프로그래머 중심적 접근에서 memory consistency model은 프로그래머에게 제공되어야만 하는 프로그램 수준의 관점에서 설명된다. 해당 모델 기반 시스템은 sequential consistency를 위반하지 않은 채로 최적화를 수행하는 정보를 사용한다. 우리의 이전 작업들은 다양한 프로그래머 중심적 접근에 대해 알아봤다. 예를 들어, data-race-free-0 (DRF0) 접근은 weak ordering이 가능케 한 최적화들과 비슷한 최적화들을 허용할 필요가 있는 정보를 탐색한다 [2]. RCsc가 이용하는 최적화 유형들에 대한 추론하는 더 간단한 방식으로 release consistency (RCsc)의 정의와 함께 properly-labeled (PL) 접근이 제공된다. 보다 공격적인 최적화를 사용하는 프로그래머 중심적 접근은 우리의 다른 작업에서 설명했다 [7,3,1,6]; 프로그래머 중심적 모델을 설계하기 위한 단일화된 프레임워크 또한 그러한 모델들의 설계 공간을 탐색하기 위해 개발되고 사용된다 [1].
프로그래머 중심적 접근을 더 정확히 설명하기 위해, 다음 섹션은 약한 순서 모델에서 사용되는 최적화들과 비슷한 것들을 가능하게 하기 위해 프로그래머에게 제공될 수도 있는 프로그램 수준 정보의 유형에 대해 설명한다. 그리고나서 우리는 그러한 정보가 프로그래머에 의해 시스템에게 실제로 얼마나 전달되는지 설명한다.
7.1 An Example Programmer-Centric Framework
약한 순서는 메모리 오퍼레이션이 data와 synchronization으로 구분될 수 있고, data 오퍼레이션은 synchronization 오퍼레이션보다 더 공격적으로 실행될 수 있다는 직관에 기초한다는 것을 상기하자. 프로그래머 중심적 접근의 핵심 목표는 synchronization과 구별되어야 하는 오퍼레이션을 정식으로 정의하는 것이다.
한 오퍼레이션이 만약 모든 순차적 일관 실행에서 또다른 오퍼레이션과 race를 형성(race condition 얘기)시킨다면 synchronization 오퍼레이션으로 정의해야만 한다; 다른 오퍼레이션들은 data로 정의될 수 있다. 순차 일관 실행을 고려해 볼 때, 한 오퍼레이션은 두 오퍼레이션(최소 하나는 write)이 같은 위치에 접근하면 다른 하나의 오퍼레이션과 race를 형성시키고, 고려중인 두 오퍼레이션 사이에는 개입하는 다른 오퍼레이션이 없다. Figure 12의 예시를 고려해보자 (Figure 5(b)의 예시와 같음). 이 프로그램의 모든 순차적인 일관 실행 안에서는, Data로의 write와 read는 Head로의 write와 read에 개입하는 오퍼레이션들에 의해 항상 분리될 것이다. 그러므로, Data로의 오퍼레이션들은 data 오퍼레이션이다. 하지만, Head로의 오퍼레이션은 다른 오퍼레이션들에 의해 항상 분리되지 않는다; 그러므로, 이들은 synchronization 오퍼레이션이다. 프로그래머는 프로그램의 순차적 일관 실행에 대해서만 추론하고 위의 정보를 제공하기 위한 모든 재정렬 최적화에 대해서는 다루지 않는다는 것을 기억해라.
시스템 설계 관점에서 보자면, synchronization으로 분류된 오퍼레이션들은 보수적으로 실행될 필요가 있는 반면에, data로 분류된 오퍼레이션들은 공격적으로 실행될 수 있다. 특별히, 약한 순서 모델이 가능케 하는 최적화들은 안전하게 적용될 수 있다. 게다가, 그 정보는 약한 순서에 사용되는 정보보다 더욱 공격적인 최적화 또한 가능케 한다 [2,13,1].
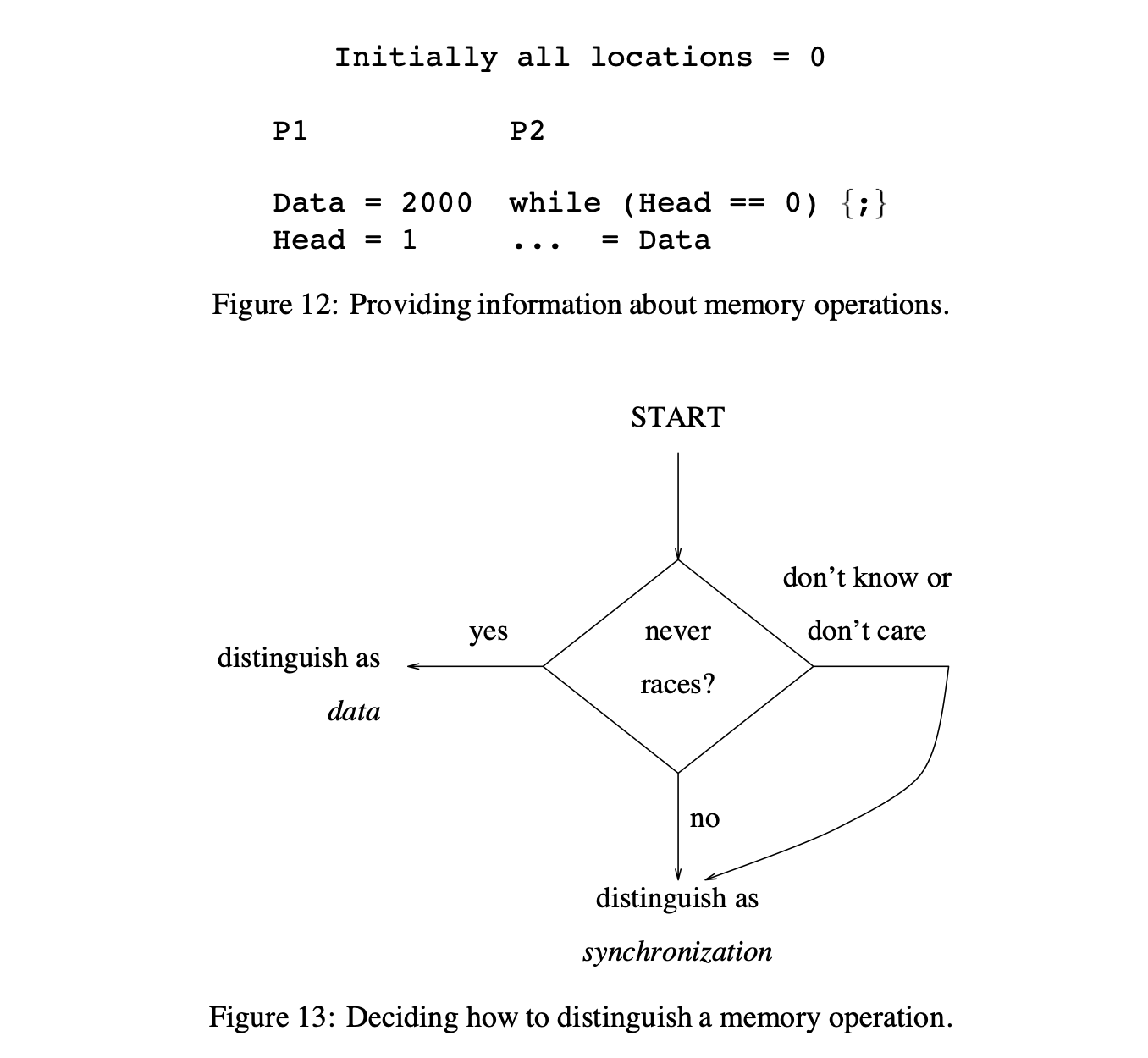
Figure 13에서 보여주듯이, 프로그래머 중심 프레임워크는 프로그래머가 synchronization 오퍼레이션으로써 race에 포함될지도 모르는 모든 오퍼레이션들을 식별하길 바란다. 다른 오퍼레이션들은 data 혹은 synchronization 중 하나로 구별될지도 모른다. 그러므로, 한 오퍼레이션은 프로그래머가 특정 오퍼레이션이 race에 포함되는지 아닌지 확신하지 못한다면 보수적으로 synchronization 오퍼레이션으로 구별될 수도 있다. 이 "잘 모름(don't-know)" 옵션은 다음의 이유들로 인해 중요하다. 프로그래머는 보수적으로 모든 오퍼레이션을 synchronization으로 구별함으로써 평범하게 정확성을 보장할 수 있다; 당연히, 이것은 모든 성능상 이점을 포기하는 것이지만 잠재적으로 초기 동작하는 프로그램에게 fast path하는 것을 가능케 한다. don't-know의 또 다른 잠재적 이득은 메모리 오퍼레이션의 부분 집합을 위한 정확한 정보를 제공함으로써 (프로그램의 성능이 중요한 영역 안에서), 그리고 남은 오퍼레이션을 위한 보수적인 정보를 간단히 제공함으로써 프로그래머가 점진적으로 성능을 조정할 수 있게 되는 것이다. 물론, 정확성은 프로그래머가 race 오퍼레이션을 data로 부정확하게 구별하는지 아닌지에 대해 보장되지 않는다.
시스템에게 적절한 정보를 제공하는 것은 메모리 오퍼레이션을 구별하기 위한 프로그래밍 언어 수준에서의 메커니즘, 그리고 하드웨어 수준에 대한 몇몇 형식 안에서 이러한 정보를 넘겨주기 위한 메커니즘 또한 필요하다. 우리는 다음 섹션에서 그러한 메커니즘을 설명한다.
7.2 Mechanisms for Distinguishing Memory Operations
이번 섹션은 이전 섹션에서 설명한 프로그래머 중심적 프레임워크가 필요로 하는 정보를 전달하기 위한 몇 가지 가능한 메커니즘을 설명한다.
7.2.1 Conveying Information at the Programming Language Level
우리는 명시적 병렬 구조와 함께 프로그래밍 언어를 고려한다. 그 언어가 제공하는 병렬 프로그래밍 지원은 doall loops와 같은 높은 수준의 병렬 구조에서 동기화를 달성하기 위한 저수준의 메모리 오퍼레이션 사용에 이르기까지일 수 있다. 그러므로, 메모리 오퍼레이션에 대한 정보를 전달하기 위한 메커니즘은 언어가 제공하는 병렬성의 지원에 달렸다.
많은 언어들이 병렬 작업 및 동기화를 위한 높은 수준의 병렬성을 명시하고, 프로그래머가 이러한 병렬성을 사용하는 것을 제한한다. 예를 들어, 병렬성이 doall loops를 통해서만 표현되도록 하는 언어를 고려해보자. doall loops의 올바른 사용은 loop의 두 병렬 반복자가 있을 때 적어도 하나의 접근이 write가 있다면 같은 위치로의 접근하지 않도록 해야 한다. 그러므로, 메모리 오퍼레이션에 대한 정보는 높은 수준의 프로그램 안의 어떠한 오퍼레이션도 race에 포함되지 않기 때문에 암묵적으로 전달된다.
약간 더 낮은 수준에서는, 그 언어가 일반적인 동기화 루틴의 라이브러리를 제공할 수도 있고, 프로그래머는 이러한 루틴을 대한 호출에 의해 동기화를 달성하는 것을 제한한다. 이 경우, 프로그래머는 프로그램 내의 다른 오퍼레이션 사이의 모든 race들을 없애기 위해 충분한 그러한 동기화 호출을 사용해야만 한다. 그러므로, doall loops의 경우와 비슷하게, 프로그래머에게 보이는 모든 메모리 오퍼레이션에 대한 정보(i.e., 동기화 루틴 안에서 사용된 오퍼레이션의 배제)는 암묵적으로 전달된다. 물론, 라이브러리 루틴의 컴파일러나 writers는 doall loops와 같은 구조들을 구현하기 위해 소개된 추가적인 오퍼레이션을 위한 오퍼레이션 유형들(i.e., synchronization 또는 data)이나 다른 synchronization 루틴이 하드웨어와 같은 저수준으로 전달된다는 것을 여전히 보장해야만 한다.
마지막으로, 프로그래머는 동기화 목적으로 프로그램 수준에서 보이는 메모리 오퍼레이션을 직접 사용할 수 있을지도 모른다 (e.g., flag 변수로 메모리 위치를 사용하기). 이 경우, 프로그래머는 오퍼레이션 타입에 대한 정보를 명시적으로 전달해야만 한다. 이렇게 하기 위한 한가지 방법은 프로그램 수준에서 이 정보를 정적 명령어와 연관시키는 것이다. 예를 들어, 언어는 코드의 특정 정적 영역을 synchronization(또는 data)이 되는 것으로 인식하는 구조를 제공할 수 있다; 그러고 나서 코드 영역에서 생성된 모든 동적 오퍼레이션들은 암묵적으로 synchronization(또는 data)로 식별될 수 있다. 또 다른 옵션은 data 또는 synchronization 특징을 공유 변수 또는 주소와 연관 짓는 것이다. 예를 들어, 언어는 프로그래머가 동기화 목적으로 사용되는 변수들을 식별할 수 있는 추가적인 타입 선언들을 제공할 수 도 있다.
프로그래밍 언어가 제공하는 메커니즘의 유형 및 일반성은 요구되는 정보를 전달하기 위해 사용의 용이성에 영향을 미친다. 예를 들어, 타입 선언은 오퍼레이션 유형을 지시하는 데에 사용되는 메소드들 안에서, 모든 오퍼레이션들이 data로 간주되는 기본 환경(특별한 지시가 없는 한) data 오퍼레이션은 더욱 빈번하기 때문에 유익할 수 있다. 반면에, synchronization 유형을 디폴트로 만드는 것은 초기 동작 프로그램을 가져오기를 더욱 간단히 만들어주고, 프로그래머가 보다 공격적으로 data 오퍼레이션을 명시적으로 선언하기를 요구함으로써 잠재적으로 에러를 줄일 수 있다.
7.2.2 Conveying Information to the hardware
프로그래밍 언어 수준에서 전달된 정보는 아래 쪽에 놓인 하드웨어에게 궁극적으로 제공되어야 한다. 그러므로, 컴파일러는 종종 고수준의 정보를 하드웨어가 지원하는 형태로 적절하게 변환해줄 의무가 있다.
프로그래밍 언어 수준에서 사용되는 메커니즘과 비슷하게, 메모리 오퍼레이션의 정보는 특정 주소 범위나 그 오퍼레이션에 호응하는 메모리 오퍼레이션 둘 중 하나와 연관될 수도 있다. 특정 주소 범위의 정보를 연관 짓는 한 가지 방법은 특정 페이지로의 오퍼레이션을 data 또는 synchronization 오퍼레이션으로 간주하는 것이다. 특정 메모리 명령어의 정보를 연관 짓는 것은 두 방법 중 하나로 가능할 수 있다. 첫 번째 옵션은 메모리 오퍼레이션을 구별하기 위해 (e.g., 추가적인 opcode를 제공함으로써) 메모리 오퍼레이션의 다중 유형을 제공하는 것이다. 두 번째 옵션은 이를 달성하기 위해 가상 메모리 주소의 사용하지 않는 높은 순서 bits를 사용하는 것이다 (i.e., address shadowing). 마지막으로, compare-and-swap 또는 load-locked/store-conditional과 같은 몇몇 메모리 명령어들은 디폴트로 synchronization으로 다뤄질 수도 있다.
대부분의 상업 시스템은 하드웨어에게 직접적으로 메모리 오퍼레이션에 대한 정보를 전달하기 위해 위와 같은 기능을 제공하지 않는다. 대신에, 이 정보는 충분한 순서 제약 조건을 부여하기 위해 하드웨어 수준에서 지원하는 명시적인 fence 명령어로 변환되어야 한다는 것이다. 예를 들어, Alpha와 같은 메모리 방벽을 지원하는 하드웨어에서 약한 순서의 동기화 오퍼레이션 시멘틱을 제공하기 위해, 컴파일러는 메모리 방벽과 함께 모든 synchronization 오퍼레이션을 앞서고 따라갈 수 있다.
8. Discussion
수많은 하드웨어 최적화를 가능케 함으로써 sequantial consistency를 가능하게 하는 것보다 relaxed memory consistency model이 더 좋은 성능을 제공한다는 강력한 증거가 있다 [9,11,6]. 메모리와 커뮤니케이션 속도와 관련된 프로세서의 속도 증가는 오직 이러한 모델로부터 잠재적인 이득을 증가시킬 것이다. 하드웨어 수준에서의 성능 이득을 제공하기 위하여, relaxed consistency model은 또한 중요한 컴파일러 최적화를 가능하게 하는 핵심 역할을 한다. 위의 추론들은 relaxed memory model을 지원하면서 Digital Alpha, Sun SPARC, IBM PowerPC와 같은 많은 상업 아키텍처를 이끌어왔다. 게다가, 거의 모든 다른 아키텍처들도 미래에 relaxed memory model을 지원한다는 약속을 나타내는 명시적인 fence 명령어들의 몇 가지 형태를 지원한다. 불행히도, memory consistency model에 관한 존재하는 문헌은 일반적인 유저나 컴퓨터 시스템의 설계자보다는 이 분야의 연구자들을 대상으로 하는 것이 대부분이라서, 방대하고 복잡하다. 이 기사는 컴퓨터 전문가들의 보다 넓은 커뮤니티에 도달하기 위한 목표와 함께, 오늘날 산업 현장에서 사용되는 memory consistency model의 대표격들과 관련된 몇 가지 이슈를 커버하기 위해 통일화되고 직관적인 용어를 사용했다.
Relaxed consistency model의 한 가지 단점은 프로그래밍 복잡도의 증가다. 이러한 복잡도의 대부분은 문헌에 나타나는 많은 사양들이 프로그래머에게 해당 모델이 가능케 하는 저수준 성능 최적화를 노출하기 때문에 일어난다. 우리의 이전 작업은 보다 높은 수준의 추상화를 사용한 모델을 정의함으로써 이 이슈에 대해 설명했다; 이 추상화는 프로그래머가 메모리 오퍼레이션에 대한 올바른 프로그램 수준 정보를 제공하는 한 sequential consistency의 환상을 제공한다. 반면에, High Performance Fortran과 같은 언어 표준화에 대한 노력은 sequential consistency와는 다른 고수준의 메모리 모델을 이끌었다. 예를 들어, 배열 인덱스 집합에 대한 계산을 지정하는 High Performance Fortran의 forall 문은 copy-in/copy-out 시멘틱을 가지는데, 여기에 한 인덱스의 계산은 다른 인덱스에 의해 계산된 값에 영향을 받지 않는다. 전반적으로, 최고의 memory consistency model 선택은 해결과는 거리가 멀고, 언어와 하드웨어 설계자 사이에 더욱 활성화된 협업에 덕을 볼 것이다.
번역 후기
인생에서 이렇게 긴 글을 번역한 적은 처음이다. 지금까지는 영어로 된 글이나 논문을 읽기만 했지 이렇게까지 번역을 해본 적이 없었다. 하면서 영어를 독해하는 실력이라든지 글에서 쓰는 투를 배울 수 있었고, 당연하게도 이번 글을 쓰게 된 요지 중 하나인 "공유 메모리 상에서 어떤 식으로 최적화를 하는지"를 잘 알 수 있었던 좋은 계기였다.
오래 걸리긴 했지만 천천히 이런 식으로 저수준과 관련된 컴퓨터 관련 지식을 쌓고 싶다.
읽어주셔서 감사합니다!
- WO에서는, (섹션 6.1에서 언급했던) 멀티 프로세서 데이터 혹은 의존성 제어와 관련된 프로그램 순서 안에서 쓰기 W 이전의 읽기 R이 주어진다면, 우리는 읽기 R이 종료되고 R에게 읽힌 쓰기가 종료될 때까지 쓰기 W는 연기된다고 가정한다. [본문으로]