![[Kernel of Linux] 14. Memory Management](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fbl6DuQ%2FbtrqFoIC8KQ%2FAAAAAAAAAAAAAAAAAAAAAD31S2CH2l5dwweiXDIKVL5ckIHfFzehYrSTECcH-N_u%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1772290799%26allow_ip%3D%26allow_referer%3D%26signature%3DhQ1jEw%252F7%252B7qc8670uLypFmXCCLE%253D)
지난 강의 요약 - File System (3)
Linux는 Unix와는 달리 많은 종류의 FS을 커버할 수 있도록 만들어졌다. 그래서 실제 physical FS layer 위에 유저를 위한 standard를 제공하기 위한 VFS(Virtual FS) layer를 얹어놨다.
VFS는 standard objects 4가지를 통해 어떤 FS든지 정의할 수 있도록 했다. superblock object / inode object / file object / dentry object. dentry를 제외한 나머지 object들은 이전에도 많이 했으니 넘어가고 dentry에 대해 알아보자.
dentry는 directory entry로 단순히 말해 path(name) components의 inode를 저장하는 것을 말한다. 이것이 필요한 이유는 작업할 때 각 파일에 접근하기 위해 필요한 I/O의 횟수가 매우 많아져 성능상 좋지 않기 때문이다. 그래서 dentry struct를 이용해 지나온 path components의 inode와 i-number를 저장하여 다시 접근할 때 빠르게 접근할 수 있도록 만든 것이다. 하지만 이런 정보를 무제한 저장할 수는 없으므로 저장 가능한 크기의 한도를 정해놓고 관리하는 dentry cache를 둔다. inode cache와 file table 사이에 위치한다.
VFS에는 이렇게 여러 다른 FS type이 달려있지만 한 가지 특별한 FS가 존재한다. 바로 /proc FS가 그것인데 실제 디스크에 존재하는 FS는 아니다. 해당 FS는 요청에 의해서(on demand)만 생성되고 내부에 존재하는 파일들은 실제 파일이 아닌 kernel function이다. 그래서 유저는 프로세스의 정보들을 살필 수도 있고 건네준 파라미터의 값에 따라 실시간으로 값들을 수정할 수도 있다.
1. Process Address Space
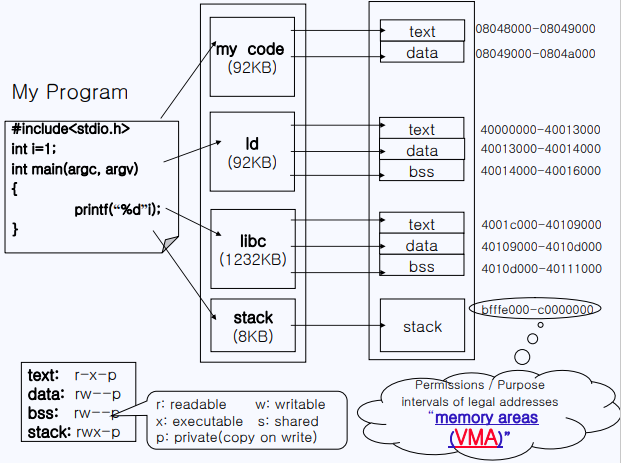
프로그램을 짜서 컴파일한 후에 실행을 시키면 메모리에 위와 비슷한 형태로 올라가게 된다. 그리고 각 영역의 권한도 설정된다. 그리고 이렇게 권한과 목적을 띤 구간을 intervals of legal addresses라고 하고 다르게 memory areas라고도 하는데 실제 physical의 주소가 아니라 가상이기 때문에 VMA (Virtual Memory Areas)라고 한다. 즉 process address space는 VMA로 이루어져 있다. 예를 들어 my code는 text, data라고 하는 VMA로 이루어져 있는 것이다.
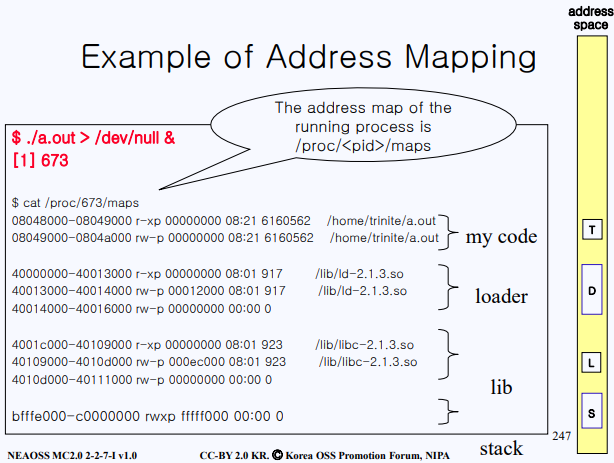
그림으로 보면 위와 같이 듬성듬성 배치되어 있다는 것을 알 수 있다.

Linux에서 PCB는 6조각으로 나뉘어 있다고 배웠다. 그 조각 중 하나인 부분이 바로 mm이다. mm struct는 해당 프로세스가 사용하고 있는 메모리에 대한 정보를 가지고 있다.
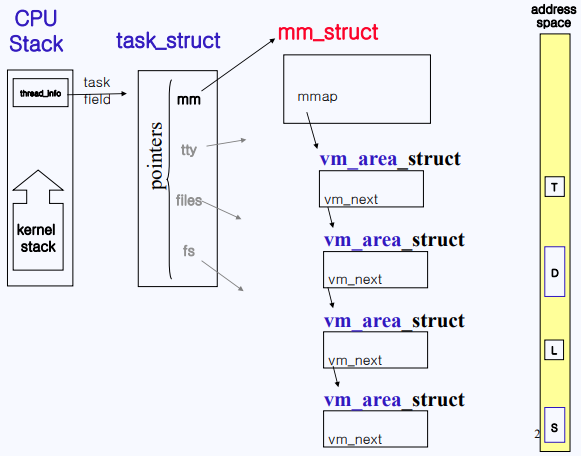
mm struct는 아까 본 process address space의 주소(VMA's address)를 가리키는 list를 가지고 있을 것이다. mm_struct에는 vm_area_struct list의 포인터를 가지고 있는데 그 변수 이름이 mmap이다. 각 vm_area_struct는 각 VMA space의 정보를 가지고 있으며 다음 vm_area_struct의 주소를 vm_next 변수를 통해 가리키고 있다.

코드로 보면 이렇게 구성되어 있다.
2. VMA (Virtual Memory Area)

프로세스마다 PCB가 있고 PCB는 task_struct를 말한다. task_struct에는 5개의 포인터 중 mm field는 mm_struct를 가리킨다. mm_struct에는 vm_area struct가 줄줄이 연결되어 있다. 하나하나의 vm_area는 그림에서 각 흰 부분에 대응한다. 안에 든 정보로는 start, end address와 permission, disk의 어느 file인지, 그리고 상황마다 적용할 operations의 시작 주소 등이 있다.

vm_area_struct는 어떻게 생겼는지 보자. 이 struct에 존재하는 대부분의 variables 이름은 "vm_"으로 시작한다.
- vm_start: interval의 시작 주소
- vm_end: interval의 끝 주소
- vm_ops: 주어진 VMA에 할당된 operations (종류를 보고 싶다면 여기 링크로)
- vm_mm: 이 VMA를 가리키는 mm_struct로의 point back
- vm_next: 다음 vm_area_struct 포인터
- vm_file: 매핑한 파일

VMA에 대하여
- definition
- legal memory address intervals
- process가 access 하는 permission/purpose가 있을 때 - content
- text, data, bss, stack, memory mapped files, ... - kernel can dynamically add/delete memory areas

위에서 소개된 필드 이외의 다른 필드 2개를 살펴보자. 먼저 vm_area_struct 구조체 안에 존재하는 vm_operations_struct type의 vm_ops 변수가 있다. 그리고 mm_struct 안에 있는 pgd_t type의 pgd 변수가 있는데 이는 page mapping table을 가리킨다.
3. Paging
a.out이라는 파일을 만들고 실행시켜 main memory에 올리고자 하는데 만약 a.out이 main memory에 전부 올라가지 못할 만큼 큰 크기를 가지고 있다면 어떻게 해야 할까.
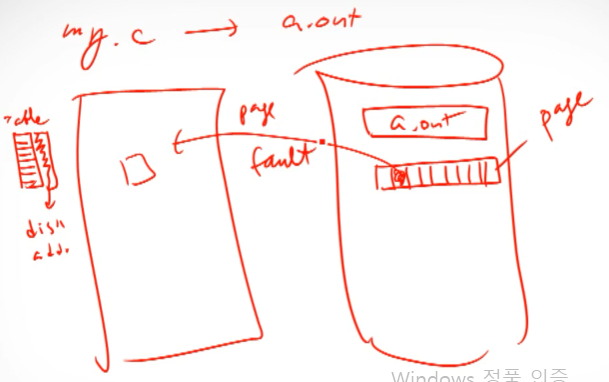
이때는 a.out을 디스크에서 일정하게 잘린 크기로 가지고 있는다. 이 일정하게 잘린 것을 page라고 한다. 이후 메모리에서 해당 page들을 관리하기 위한 table을 생성한다. table의 index마다 page들의 disk address를 저장한 뒤에 모두 못 갖고 왔다는 표시를 해둔다. 그리고 실제로 실행했을 때 원하는 page가 현재 memory에 올라와 있는지를 검사해서 있다면 쓰면 되고, 없다면 page fault가 발생해서 disk로부터 해당 page를 가져와 memory에 올리고 table에 가져왔다는 표시를 한다. page fault가 발생해서 memory의 아무 빈 공간에 올라온 후에는 해당 memory의 address도 table에 저장한다. 이 table을 page table, page mapping table이라고 한다.

page table에서 page의 특정 부분을 가리키기 위해서는 몇 번째 page인지, 그리고 그 page에서 몇 번째 byte(offset)인지를 나타내 주어야 한다. 하나의 주소에서 이 두 가지를 모두 표현하고자 할 때, 몇 bit 씩 나누면 좋을 것인지 고민해봐야 한다. offset의 크기를 정하는 것은 비교적 쉽다. 설정한 page의 크기를 포함할 수 있는 bit 수를 가지면 되기 때문이다. 4K 크기의 page로 설정되어 있다면 page의 offset을 표현하기 위해 필요한 bit 수는 12-bit만 있으면 된다. 위의 계산은 각 machine에서 가지는 address의 크기마다 가질 수 있는 page의 총개수가 몇 개 남는지를 계산한 것이다.
16-bit는 4-bit가 남으니 2^4개만큼의 page를 가리킬 수 있다. 나머지도 계산해보면 알겠지만 32,64-bit machine에서는 이 page entry의 개수가 너무 크다.

위에서 계산한 값을 토대로 실제 process가 사용하는 memory 영역은 어떻게 되는지 그림으로 보면, too large space per each process, too sparse, too much memory wasted for (unused) page tables 하다는 것을 알 수 있다.

32-bit 머신을 기준으로 한 예시다. page는 몇 개만 사용하면 되는데 table의 크기가 너무 커서 쓸데없는 빈 공간이 엄청나게 많이 남아있는 모습을 확인할 수 있다.
이렇게 하면 공간의 낭비가 엄청나니 전부 만드는 방법 말고 더 잘게 쪼개서 필요할 때만 만들어서 주는 방법을 선택했다. 예제 기준으로 page number(20-bit)을 절반으로 쪼개 dir number(10-bit)로 만들어주었다. dir에서 빈 공간은 나머지 page number(10-bit)를 위한 공간을 만들어주지 않는다.

여기까지의 내용을 정리해보자.
process는 process's metadata인 PCB를 가진다. linux에서는 task_struct 구조체가 PCB 역할을 하는데 task_struct 하나로는 너무 커서 6개의 작은 부분으로 쪼개 놨다. 그중 한 부분이 바로 mm(main memory)에 대한 것이다. 따라가 보면 mm_struct 구조체로 관리되고 있다. process가 현재 차지하고 있는 메모리 영역을 나타내기 위해 vm_area_struct 구조체로 필요한 정보들을 저장하고 있다. 그리고 pgd(page directory) 필드를 통해 page를 관리하고 있다. 관리하는 방법은 위에서 설명한 대로다.
4. 강의 마지막 정리

결국 지금까지 배운 것은 linux라는 platform을 이해하기 위한 빙산의 일각을 배운 것이다. Ext2, Ext3, NFS와 같은 파일 시스템과, TCP/IP, Camera, GPS와 같은 plug-in-modules에 대한 구현을 배우지 않은 이유는 이런 소프트웨어를 하드웨어에 꽂아 동작시키기 위한 준비를 해주는 방법을 설명했기 때문이다. 소프트웨어 구현 방식에 대해서는 프로그래머가 원하는 상황과 동작에 맞춰 하드웨어와 인터렉트 할 수 있도록 만들어 둔 것이 바로 linux라는 platform인 것이다.
소프트웨어에는 두 가지 종류가 있다. 하나는 modular, 다른 하나는 monolithic이다. modular는 조그만 부분만 가져와도 특정 부분을 바꿀 수 있는 반면에, monolithic은 조그만 부분을 바꾸기 위해서는 전체에 대해 이해하고 있어야만 가능하다.
modularity가 있다는 것은 독립적으로 디자인되었지만 같이 동작할 수 있다는 뜻이다. 이때는 두 부분으로 나누어야 하는데 하나는 platform, 다른 하나는 module이다.

monolithic(CSS; Closed Source Software), modular(OSS; Open Source Software) 두 개를 그림으로 비유한 것이다.

이렇게 linux platform을 만들어 놓으면 그 안에 여러 modules를 이식할 수 있는 것이다.

예를 들어 안드로이드에서는 저런 식으로 구성되어 있을 것이다.
5. 후기
여기까지 「Linux Kernel Development (Robert Love)」 책을 기반으로 한 고건 교수님의 강의가 끝이 났다. 책의 모든 내용을 다루지는 않았지만 내가 여태까지 두루뭉술하게 알고 있던, 혹은 몰랐던 개념들을 똑똑히 집어 설명해주신 것에 너무 감사했다.
이젠 지금까지 정리했던 내용들을 복습하며 잊지 않고 책에서 다루지 못했던 부분, 그리고 강의가 있었던 시점과는 달라진 부분들을 유념하며 더욱더 심화된 내용을 알아갈 것이다. 그리고 꼭 linux kernel에 기여하는 순간이 왔으면 좋겠다.