![[Kernel of Linux] 13. File System (3)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2F8Aif6%2FbtrqIsJXamy%2FAAAAAAAAAAAAAAAAAAAAAIKP882ZF728jamdY9qn_a5ojJmiYKMdmPEcA6sNx26e%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1772290799%26allow_ip%3D%26allow_referer%3D%26signature%3DahGvQe8tCmfYIPGq%252BeiWmD1YIgU%253D)
지난 강의 요약 - File System (2)
디스크는 inode와 data를 저장하는 부분으로 나뉘어 있다. inode 0번째는 root directory를 의미한다.
open("/a/b") 이렇게 시스템 콜이 불렸다면 처음에 root directory file을 열어서 밑에 있는 inode 포인터 리스트를 가져온다. 파일 중 a file을 가리키는 inode 포인터를 찾았다면 또 거기서 아래로 내려가 찾는다. 그렇게 b file까지 오게 되면 b를 위한 offset을 저장할 file struct를 만들고 나서 이를 가리키는 포인터를 커널에 있는 u_ofile[] array에 저장한다. 포인터를 저장한 이 array의 index를 바로 fd(file descriptor)라고 한다.
디스크에 데이터를 저장하는 방식은 어떨까. 바로 Balanced tree 자료구조의 형태를 띤다. 전체 디스크의 크기와 나눠질 섹터의 개수를 알면 각 섹터를 가리키기 위해 필요한 인덱스 정수의 크기를 알 수 있다. 디스크에는 데이터의 실제 컨텐츠 부분뿐만이 아니라 섹터의 인덱스를 저장할 영역 또한 포인팅을 위해 필요하므로 단순히 한 섹터가 다른 모든 섹터를 인덱스만으로 채워 저장하기에는 공간이 역부족하다. (도식은 이전 포스팅을 참고하길 바란다.)
C언어에서 fd와 *FILE은 차이가 있다. fd는 파일을 열고 실제 file에 접근할 수 있는 값이고, *FILE은 유저 프로세스 내부에서 파일을 열고 이를 다룰 때 좀 더 효율적으로 일을 처리하기 위해 존재하는 FILE struct를 의미한다. 이 구조체 내부에는 버퍼가 있어서 미리 데이터를 읽어 저장시킨 후 프로세스가 요청할 때마다 그 크기만큼을 리턴 시켜준다. 이렇게 하는 이유는 유저에서 커널로 스위칭되는 오버헤드가 크기 때문에 이렇게 하는 것이다.
디스크에는 inode block, data block 말고도 super block이 존재한다. 이 block이 가지고 있는 정보는 "inode block의 크기, data block의 크기, inode free space's head pointer, data free space's head pointer"가 있다.
마운팅(mounting)이란 한 파일 시스템의 루트를 다른 파일 시스템의 특정 inode와 동일시하는 작업이다.
1. Virtual File System (VFS)
지금까지 우리가 배운 파일 시스템은 전부 Unix에서 사용한 방식이었다. 이제는 리눅스에서는 어떻게 파일 시스템을 사용하는지에 대해 배운다.

이전에 배웠던 것을 간단하게 다시 정리해보면, Unix에서의 파일 시스템은 Bootblock, Superblock, Inode list, Data block으로 이루어져 있고 특히 Inode list는 per File Metadata, Superblock은 per File System Metadata라고 표현 가능하다.
그런데 여기서 파일 시스템이라고 다 같냐고 물으면 그건 아니다. 예를 들어 superblock에 있는 free space list의 구현은 회사마다 다르다. bitmap처럼 다룰 수도 있고 linked list 형태로 존재할 수도 있고, 아니면 tree로 되어 있을 수도 있다.
이렇게 회사마다 다르니 이 파일 시스템을 다른 파일 시스템에 꽂으려 하면 동작하지 않는다. 그래서 처음 산 USB 같은 경우 처음 컴퓨터에 꽂으면 현재 파일 시스템에 맞게 포메팅(formatting)을 진행한다. 이런 디바이스 중 예외가 있다면 후발 주자로 나온 DVD 같은 경우다. DVD에 있는 파일 시스템은 표준화가 되어 있어 어디에 넣든 다 동작한다.

위와 같이 Linux, DOS, Solaris 사에서 만들어진 각기 다른 파일 시스템이 있을 때, Unix 시절에는 동작하지 못했다. 하지만 Linux는 다른 파일 시스템도 수용 가능하게 만들어지면서 mounting 또한 자유롭게 된다. 그래서 pathname이 곧 FS type을 결정하는 것이다.

"cp /a/b/c /x/y/z"라는 명령어를 쉘에 입력했다. cp는 user command(1), 즉 program이다. 그래서 내부에서는 대략 다음과 같은 로직으로 동작할 것이다. 먼저 복사할 파일을 열고(open) 새로 만들 파일을 만들어주고(create) 열었던 파일에서 데이터를 읽어온 다음(read) 새로 만든 파일에 쓸 것이다(write). 저기서 사용하는 명령어들은 어떤 파일 시스템이든지 같다. 하지만 다른 FS는 다르게 동작해야만 하는데 이는 어떻게 해결한 것일까?

Linux에서는 유저가 FS와는 상관없이 standard 하게 사용할 수 있도록 서로 다른 실제 physical FS layer 위에 하나의 가상 FS(Virtual FS, VFS) layer를 만들어놓았다. VFS는 단순히 각 기능에 대한 추상화를 해놓았을 뿐이고 실제 read/write와 같은 기능은 각 FS마다 가진 실제 구현을 따르도록 만든 것이다.
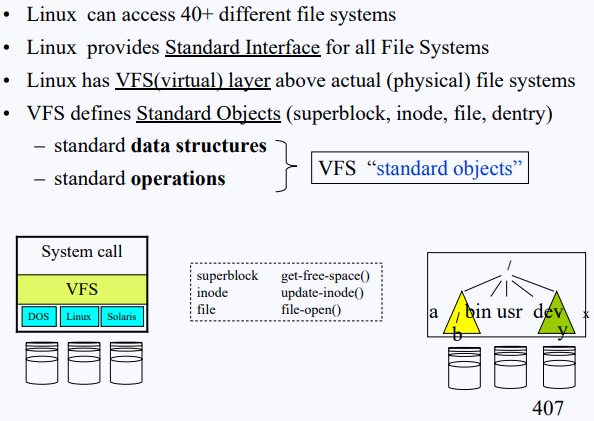
- Linux는 40개 이상의 다른 FS을 지원한다.
- 모든 FS에 대해 standard interface를 제공한다.
- VFS layer는 실제 physical FS layer 위에 존재한다.
- VFS는 Standard Objects로 정의한다. (superblock, inode, file, dentry)
- standard data structures
- standard operations
2. Linux VFS Standard Objects

Linux는 어떤 FS type이든지 4가지 Standard Objects를 정의한다.
- superblock object
- file system control block - inode object
- file control block - file object
- offset and interaction between (open file - process) - dentry object
- mapping info: (pathname -> inode)
ex) /a/b/c/d/e -> inode #7
* Disk resident object = superblock, inode object / Memory resident object = file, dentry object
2.1 Dentry Object

다른 Object들은 이전에 설명한 것과 같다. 추가적인 정보를 원한다면 자료의 412~416p를 살펴보자.
path components라고 해서 각 path에서 끊어서 볼 수 있는 각 파일들을 말한다. 위 예시를 기준으로 e 파일까지 가기 위해서는 엄청난 노력을 한 뒤에 도달할 수 있다. 하지만 해당 e 파일 위치 근처에서 작업할 때 거기까지 계속 처음부터(root부터) 타고 내려가야 한다면 많은 disk I/O가 발생할 수밖에 없다.

이를 해결하기 위해서는 각 pathname components마다 inode를 save 하면 좋을 것이다. 그래서 각 파일에 대한 inode와 i-number를 저장할 자료구조가 존재하는데 이것이 바로 dentry(Directory Entry) struct다.

기존에는 이런 식의 구조를 띠었다.
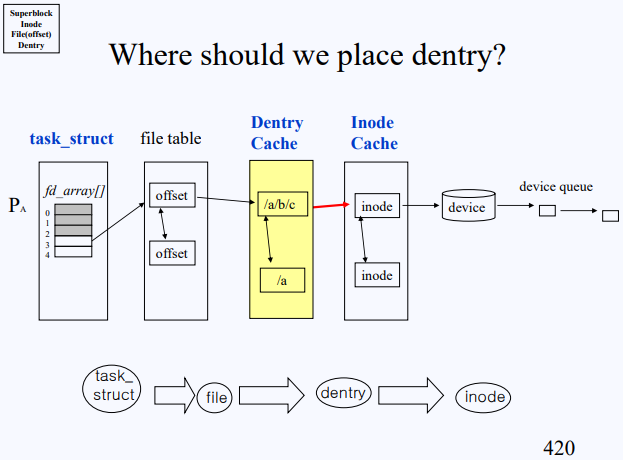
dentry가 끼어들고 나서는 이런 구조다. 하지만 그렇다고 해서 지나온 모든 path components에 대한 정보를 dentry에 저장하기에는 공간이 부족하다. 그래서 크기를 잡아두고 한도 개수를 넘어서는 건에 대해서는 알고리즘에 의해 정리되도록 한다. dentry를 위한 이 공간을 dentry cache라고 한다. 위치는 filie table과 inode cache 사이에 있다.
3. /proc file system

VFS 밑에는 Ext2, Ext3, Ext4, NFS, ... 등 여러 FS type이 존재한다. 그런데 여기에 /proc이라는 특이한 FS이 하나 존재한다. 그 특징을 살펴보자.
- special, software-created, dynamic file system
- disk에 저장되어 있는 FS이 아니다.
- /proc은 수요가 있을 때 그제야 만들어진다. (ex. ls /proc)
- /proc 밑에 있는 각 file들은 사실 kernel function이다.
- user에게 data/statistics를 export 하기 위해 커널에 의해 사용되는 FS다.
- kernel parameters를 가지고 real time으로 바꿀 수 있다.