![[Kernel of Linux] 12. File System (2)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FrDHER%2FbtrpKDT7owF%2FAAAAAAAAAAAAAAAAAAAAABOcSeEPiUIGimP0hOwSLgrMgJdo_bWnQd102K2PbvYc%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1772290799%26allow_ip%3D%26allow_referer%3D%26signature%3DgptbXbF35E92g1kJ0QxWM8D6VFc%253D)
지난 강의 요약 - File System (1)
linux에는 파일과 파일을 표현하는 메타 데이터가 있다. 메타 데이터에는 여러 정보가 들어있는데 그중에서 중요한 정보 중 하나로 offset이 있다. 파일은 sequence of bytes라고 정의하고 있는 만큼 파일을 읽을 때 sequential 하게 읽는다. 이때 offset을 보고 어디서부터 읽을지 결정한다.
파일을 storage에 저장할 때 연속적으로 저장하는 방식을 사용할 수 있다. 이 방식의 장점은 access 할 때 빠르게 접근할 수 있지만 단점으로는 외부 단편화(external fragmentation)가 발생하여 관리가 어렵다. 다른 저장 방식으로는 storage를 일정 크기로 잘라놓은 다음에 파일이 저장된 섹터의 주소를 기억하는 것이 있다. 장점은 외부 단편화 현상이 없어지므로 저장 공간을 효율적으로 관리할 수 있지만 단점으로는 이 섹터의 주소를 기억하는 것의 비용이 커질 수 있다는 것에 있다.
여기서 여러 프로세스들이 하나의 파일에 접근하려는 상황을 생각해보자. 모두 그 파일의 데이터를 복사해서 다루기에는 메인 메모리의 용량도 부족하고 비효율적이라는 것을 쉽게 상상할 수 있다. 이때 사용할 수 있는 방식이 프로세스마다 파일의 메타 데이터를 복사해서 가지고 있는 것이다. 그런데 여기서도 생길 수 있는 문제점으로는 파일에 서로 다른 operatoin을 요청할 때 혼란을 야기할 수 있다는 것이다. 이를 위한 해결책은 파일의 메타 데이터 중에서 공유해도 되는 것은 공유하고, 공유하면 안 되는, 즉 I/O 시 달라야 하는 offset 같은 정보들은 각자 가지고 있는 식으로 구현하면 된다.
지금까지 언급한 정보들을 토대로 구성된 파일의 자료구조를 살펴보면 inode 구조체를 파일마다 생성해놓고 공유하고, file 구조체를 각자 가지고 있는 것으로 offset을 관리한다. 여기에 추가로 device switch table이 있다. devswtab[] array의 형태로 존재하는데, 존재 이유는 지금까지는 모두 구분 없이 다 같은 file로서 취급되었다면 이 테이블을 통해서 device를 실질적으로 구분해서 동작하게 만들어주는 부분으로 만들어주기 위해서이다.
1. File Descriptor

디스크는 inode & data 두 부분으로 나뉘어 있다. 부팅을 하게 되면 가장 먼저 올라오는 inode 0는 root directory file이다. 여기서 만약 open(/a/b)라는 시스템 콜이 불렸다면 어떻게 될까.
먼저 root directory file의 inode의 포인터들을 갖고 오게 될 텐데 이것들이 바로 root directory file의 contents다. 디렉터리의 데이터는 '파일의 이름 + 그 파일의 i-number'로 구성되어 있다. 예를 들어 a 파일의 i-number가 7이라면 디렉터리 데이터의 8번째 데이터라는 뜻이다. a라는 파일을 찾았으니 이제는 다음 단계로 넘어간다. a도 directory file이므로 root에서 했던 것과 마찬가지로 a의 inode data를 가져오고 그 데이터의 포인터를 따라가서 b 파일을 찾는다. b의 i-number는 3이므로 a의 4번째 data block을 찾아서 가져오게 된다. 여기까지 open()을 할 준비를 마쳤다.
이제는 b를 위한 file struct를 만들어줘서 offset을 설정한다. 이후 file struct가 해당 파일의 inode struct를 가리키게 만든다. 그리고 마찬가지로 이 file struct를 open()을 호출했던 프로세스가 가지도록 만들건대 PCB 내에 존재하는 array에다가 저장한다. fd(file descriptor) 순서는 open()을 호출한 순서대로 만들어진다.

PCB 내에 존재하면서 fd table의 역할을 하는 이 array가 바로 u_ofile[] array다. 그리고 각 프로세스마다 갖고 있는 정보다. fd는 open() 이후 받는 리턴 값이다.

open()을 했으니 이제는 그 file에 access를 할 수 있게 된다. read()/write()를 호출할 fd를 통해 순차적으로 file struct, inode struct, 그리고 devswtab array를 거쳐 실질적인 디바이스 핸들러의 시작 주소를 얻을 수 있다. file descriptor 이외에도 file handler라는 것이 존재한다. 이는 fd 앞에다가 다른 정보(Hostname, PID)를 추가적으로 알려준 것이다.
그리고 여기서 open() 시스템 콜을 제외한 다른 file 관련 시스템 콜들은 pathname 파라미터를 사용하지 않는다. 그 이유는 단순하다. pathname을 통해 디스크에 access 하려면 너무나도 많은 오버헤드가 발생한다. inode를 읽어 들이고 file struct를 만들고 이 file struct의 포인터를 process에게 주고,... 등 read(), write() 같은 시스템 콜에게도 이런 식으로 접근하게 하면 성능상 좋지 않을 수밖에 없다. 그래서 한 번 열 때 그 fd를 저장해놨다가 다음번에 사용하면 이를 해결할 수 있다.
2. Balanced tree

데이터베이스를 구현하려는 한 프로그래머가 있다. 디스크의 크기는 10GB, 한 섹터의 크기를 1KB라고 정의해보자. 그럼 총 10,000,000 섹터가 있어야 한다. 자릿수마다 구분해서 볼 때, 섹터별로 구별하기 위해 필요한 bit는 000(숫자 0 3개)을 표현하기 위해 10-bit다(2^10=1024). 이게 2개 있으니 20-bit고, 나머지 10은 4-bit가 필요하므로 총 24-bit를 필요로 한다. 그러니까 각 고객의 정보가 담긴 섹터에 접근하기 위해 필요한 인덱스의 크기가 24-bit라는 것이다.

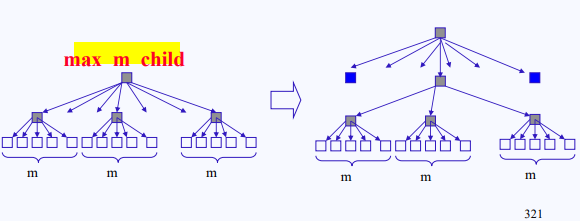
하나의 섹터는 1024-bit(1K)니까 24-bit으로 나누면 한 50개 정도의 다른 섹터 포인터를 저장할 수 있다. 하지만 이걸로는 전체 고객의 수를 절대 감당할 수 없는 수치다. 그래서 같은 형태의 트리를 계속 이어 붙인다.

그럼 그것들을 이을 또 다른 섹터가 필요하니 그 위에 계속 쌓다 보면 루트 노드가 하나 생길 때까지 이어질 것이다. 이렇게 여러 갈래로 뻗은 tree를 m-way tree라고 한다. 그런데 균형이 안 맞는 형태로 존재할 수도 있다. 하지만 여기서는 균형이 맞도록 만든 상태다. 이걸 Balanced tree(B-tree of order m)라고 한다.
번외로 이것도 너무 많다 싶으면 10개 포인터 정도만 가지는 인덱스를 쓰는 B-tree도 있는 이 인덱스를 마스터 인덱스(master index)라고 한다.
3. fd vs. FILE in C

하지만 생각해보면 지금까지 C언어를 이용해 파일을 다루는 소스 코드를 짤 때에 fd를 사용해서 구현한 적은 거의 없었다. 대부분 FILE을 이용했기 때문이다. 그렇다면 둘의 차이는 무엇일까?

파일과 관련된 시스템 콜에는 위와 같은 것들이 있다. 하지만 보통 시스템 콜을 쓰지 않고 라이브러리 함수인 scanf(), gets(), getchar()와 같은 것들을 사용해왔다. 이미 배웠다시피 라이브러리 함수들은 I/O를 수행하지 못하기 때문에 시스템 콜을 통해 커널에게 부탁하는 수밖에 없다.

시스템 콜과 라이브러리 콜의 관계는 표와 같다. 이름 맨 앞에 f가 없으면 터미널 대상, 있으면 파일을 대상으로 하는 라이브러리 함수다. 위의 예시는 모두 read()라는 공통된 시스템 콜을 사용한다. 커널에서는 fd를, user는 *FILE을 사용한다.

본격적으로 둘의 차이를 알아보자. user process에서 코드를 작성하고 실행하는데 코드 내부에는 fopen(), fread()와 같은 파일 관련 라이브러리 함수를 사용하는 중이다. 이 함수들은 실행될 때 추가적으로 생성하는 것이 있는데 이것이 바로 FILE 구조체다. 이 구조체 안에는 local buffer가 존재하는데 그 내용으로는 count, pointer 같은 것들이 있지만 제일 중요한 file descriptor(fd)에 대한 것도 존재한다. 이 fd를 따라가면 우리가 배웠던 내용대로 접근을 하게 되는 것이다.

각자 어디서 어떻게 사용되는지 예시를 통해 살펴보도록 하자.
- a.out 바이너리 안에서 fopen("/a/b/c") 라이브러리 함수를 호출한다.
- fopen() 함수 안에서는 /a/b/c를 위한 FILE struct를 만든다.
- 그리고 open("/a/b/c") 시스템 콜을 invoke 한다.
- 이후 커널에서는 table을 set up 하고 fd를 리턴한다.
- fopen() 안에서는 리턴 받은 fd를 *FILE에 저장하고 *FILE을 리턴한다. - a.out은 *FILE을 저장한다.
- 나중에 사용할 때에는 *FILE을 사용한다.

하지만 왜 굳이 이런 식으로 사용을 하는 것일까? 이유는 간단하다. 시스템 콜이 invoke 되고 나서 커널에서 여러 처리를 한 후에 다시 돌아오는 프로세스는 오버헤드가 큰 일이다. 그렇기 때문에 미리 BUFSIZ 만큼을 가져다가 저장한 뒤에 원하는 크기만큼 알려주면 그만큼 속도가 증가할 것이다.
getchar() 함수의 내부 모습을 보자. local buffer와 local buffer의 포인터 변수인 bufp, local buffer에 남은 character 수를 나타내는 counter 변수가 있다. 구현부에는 counter를 체크하면서 아직 줄 데이터가 local buffer에 남아있다면 하나를 돌려주고, 없다면 어쩔 수 없이 read()를 통해 다시 읽어온다. getchar()의 경우는 read()를 통해 읽어올 때 터미널에서 stdin(fd=0)을 통해 가져오게 된다.

모든 라이브러리 I/O 함수들은 시스템 콜을 부를 수밖에 없다. 그래서 라이브러리 함수는 시스템 콜의 front-end면서 user에게 편의성을 제공하고 performance를 최적화시켜준다.
정리하자면 FILE struct는 라이브러리 함수에서 user에게 performance를 향상해주기 위해 존재하고, fd는 실질적으로 file에 접근할 수 있는 구분자 역할을 하는 것이다.
4. File System in Disk

지금까지는 disk에 inode와 data를 저장하는 두 공간이 존재한다고 했었다. 실은 여기에 superblock이라는 영역이 하나 더 존재한다. superblock은 free space, global 두 가지 정보를 제공한다. global 정보로는 inode, data block 영역의 크기 같은 게 있고, free space는 inode, data 영역의 free 영역에 대한 정보를 가지고 있다.

inode나 data나 둘 다 각각의 cell은 동일한, 고정된 크기를 갖고 있다. 각자 같은 크기의 master index를 소유하고 있기 때문이다.
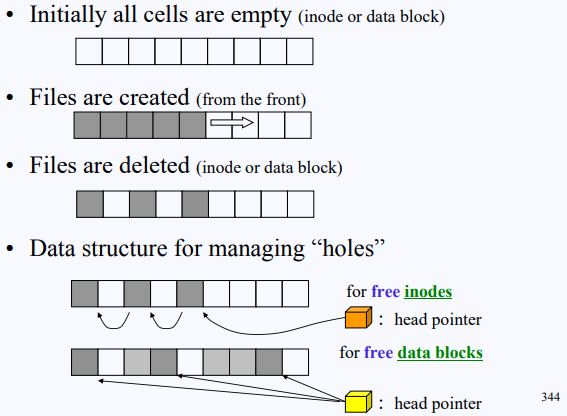
두 block의 구분 없이 같은 cell의 입장에서 살펴보자. file이 생성되어 계속 채워지다가 중간중간 지워지는 일도 생길 것이다. 중간에 없어진 hole들은 알아뒀다가 나중에 사용해야 공간에 낭비가 없다. 그래서 free space를 관리하기 위해 free space들을 linked list 형태로 구현해서 head pointer로 가리키고 있어야 한다. inode, data block 각각 해서 두 개를 가지고 있어야 한다.
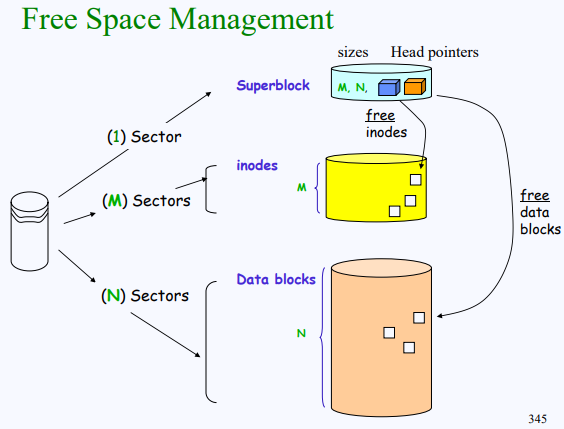
이 head pointer들은 supber block이 가지고 있다. 이렇게 해서 super block은 inode block과 data block의 크기인 M, N과 각 free spaces의 linked list를 가리키고 있는 head pointers를 가지고 있다.

위와 같은 방식으로 disk의 데이터에 접근한다는 것을 이해할 수 있다.
5. Mounting

하나의 파일 시스템은 (Bootblock), Superblock, Inode list, Data block으로 이루어져 있다. 하지만 이런 파일 시스템은 하나가 아니라 여러 개가 존재할 수 있다. 그렇다면 도대체 어떤 파일 시스템이 루트 파일 시스템인지 정해야 하는 문제가 생긴다.
Windows에서는 콜론(:)으로 구분하지만 Unix에서는 하나를 찍어서 그걸 루트 파일 시스템으로 사용한다. 위 그림을 예시로 들자면 노란색 파일 시스템이 루트로 선택되어 구성된 모습이다. 그리고 나머지 다른 파일 시스템으로의 접근은 루트로부터 따라 내려가면서 접근할 수밖에 없다. 이렇게 접근하도록 구성하는 방법은 루트 파일 시스템을 제외한 나머지 파일 시스템의 각 루트 inode를 상위 파일 시스템의 특정 inode와 동일시하는 것이다. 이를 mounting 한다고 한다.

mounting을 해주는 시스템 콜도 존재하는데 mount() 시스템 콜이 그것이다. 파라미터도 무엇(dev special file)을 어디(mount point)에 mount 할 것인지를 알려주면 된다.